
È stato detto molto riguardo l’architettura Polaris di AMD e di come evolva nella nuova generazione di GPU, ma non interpretate male: la cosiddetta “quarta generazione” non cambia nessuno dei principi fondamentali di GCN (Graphics Core Next), aggiornando semplicemente alcuni elementi per aumentare le prestazioni con carichi di lavoro in DX11, DX12, OpenGL e Vulkan.
Ancora più importante, è l’incredibile passo in avanti fatto in termini di efficienza, parzialmente ottenuto grazie al nuovo processo produttivo di Samsung FinFET a 14 nm.

Uno dei motivi principali per cui stiamo assistendo ad un balzo in efficienza con queste nuove generazioni di GPU (sia di AMD che di NVIDIA) è il passaggio a nuovi processi produttivi (14 nm per AMD, 16 nm per NVIDIA).
Mentre fino a qualche anno fa era possibile assistere ad una riduzione della grandezza dei transistors su base annua, nel 2011 il fenomeno ha raggiunto uno stop improvviso. All’epoca, fu introdotto il processo produttivo a 28 nm ma a causa di alcuni ostacoli incontrati da entrambe le parti, è stato difficile ottenere progressi tecnologici, per la maggior parte a causa dell’enorme volume di vendite degli smartphone, sottraendo risorse e tempo al mercato.
Sebbene sia nato come processo produttivo particolarmente inefficiente, con una densità di transistors elevata rispetto ai precedenti 40 nm (2009), le ultime incarnazioni (Maxwell per NVIDIA, Granada e Fiji per AMD) sono risultate particolarmente power-efficient, grazie al lavoro degli ingegneri che hanno saputo ottimizzare la potenza in rapporto alla superficie, diminuendo allo stesso tempo la produzione di calore.
I 14 nm, d’altro canto, rappresentano un enorme salto di qualità per AMD, che è adesso capace di sfruttare le lezioni imparate con l’architettura a 28 nm, migliorandola per il nuovo “nodo”.
L’architettura GCN di quarta generazione verrà ritrovata, al momento, su due chip: Polaris 10 e Polaris 11. Per questa review, daremo uno sguardo nell’insieme al più grande e performante chip P10, mentre parleremo del P11 in occasione della review della RX 460. In questa iterazione, il processo produttivo (pp) di Samsung a 14nm di tipo FinFET (i transistors sono 3D, non planari) ha permesso di contenere ben 5.6 miliardi di transistors in un die particolarmente compatto.
Per rendere meglio il paragone, abbiamo circa lo stesso numero di transistors della R9 390X nello spazio del processore grafico di una HD 7790. Incredibile, no?
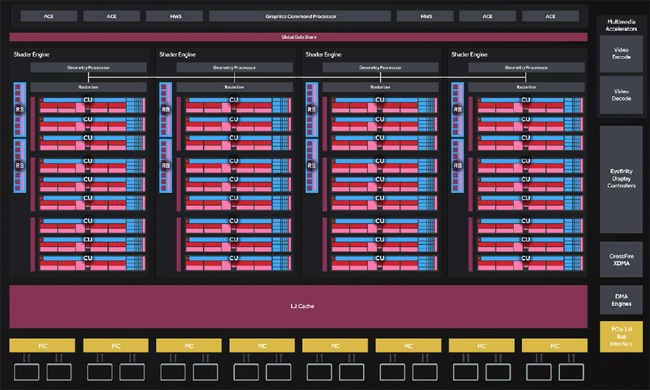
Cosa comportano 5.66 miliardi di transistors in un die di circa 243.3mm²? Beh, un design architetturale che assomiglia molto ad una versione leggermente ridotta di un Hawaii Pro, ma infinitamente più efficiente. Una cosa da evidenziare è che questa è la versione “full size” di Polaris 10, e quindi non ci saranno altre schede “unlocked” o “revisioni” da questo core in particolare.
Sotto una prospettiva di alto livello, Polaris 10 ospita 4 Geometry Processors, ognuno dei quali ospita 9 di 36 Compute units, per un totale di 36 CU. Essi sono configurati in modo da funzionare interconnettivamente grazie all’utilizzo di un GCP, un Graphics Command Processors. Se analizziamo esclusivamente il design del chip, non sono molte le differenze con l’iterazione precedente (quella utilizzata da Tonga e Fiji) della nuova architettura, ma è sotto al “cofano” che si nascondono le modifiche capaci di aumentare le IPC (Instructions-per-clock, praticamente la potenza di calcolo), dove aggiustamenti “micro” consentono l’aumento di efficienza di calcolo “macro”.
Innanzitutto, tra questi cambiamenti figura un miglioramento nel modo in cui ogni Geometry Processor gestisce i carichi di lavoro per ogni blocco. Qui, c’è un enorme salto generazionale ottenuto grazie ad una miglior comunicazione con le unità di calcolo, in modo da eliminare i momenti “morti” nella pipeline di elaborazione.
Anche la gerarchia di caching di Polaris vede alcuni cambiamenti drastici al suo layout: la quantità di cache L2 raddoppia arrivando a 2 MB, praticamente raddoppiando la quantità presente in Hawaii, e nonostante alcune delle cache per le istruzioni siano state “sparse” su tutto il die, la banda passante è stata migliorata e in alcuni casi duplicata. Ciò è particolarmente importante in quanto una maggiore efficienza di caching rimuove parte del carico dal bus a 256 bit, che è suddiviso in 8 memory controller da 32 bit.
Una delle aree che non ha visto molti cambiamenti è il Back-End di render: sebbene ci siano stati alcuni aumenti nelle performance di ogni singola ROP, quest’area potrebbe rappresentare un collo di bottiglia, con sole 32 ROP invece di 64 come sulle schede basate su Hawaii e superiori.
Su una prospettiva a larga scala, noterete inoltre che sparisce il blocco relativo alle funzioni TrueAudio, liberando spazio sul die per una maggiore efficienza di calcolo in rapporto alle dimensioni del chip. Questa funzione è adesso gestita direttamente dagli shaders, ma ne parleremo tra poco nel dettaglio. In aggiunta, è presente un nuovo display controller con supporto nativo a HDMI 2.0b e DisplayPort 1.4, insieme ad un blocco multimediale (encoding e decoding di formati video, perlopiù) fortemente rivisto.
Ultima novità ma non per importanza, la possibilità di apportare modifiche firmware tramite driver, grazie alla quale sarà possibile “evolvere” Polaris ogni qualvolta saranno richieste nuove funzionalità. Tale procedura è stata utilizzata per cambiare la gestione di corrente delle fasi e risolvere il problema di alimentazione dei primi giorni.
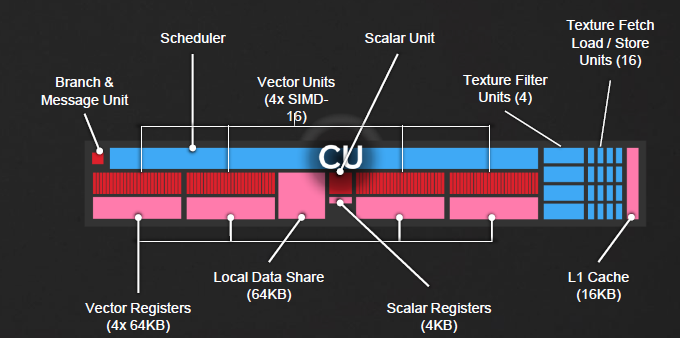
Molti dei cambiamenti di Polaris sono stati effettuati a livello della singola Compute Unit. Così come altri chip basati su GCN, ogni CU include 64 Stream Processors suddivisi in gruppi da 16, quattro cache per registri da 64 KB, 4 unità textures con funzionalità di caricamento e salvataggio ed un blocco di cache L1 dedicata da 16 KB.
La priorità di AMD, a questo giro, è stata di aumentare l’efficienza intrinseca di ogni shader, e ciò è stato ottenuto con un algoritmo migliorato di prefetch delle istruzioni. Esso migliora l’efficienza accorciando “l’occlusione” delle pipeline e rende il caching delle istruzioni più lineare.
Ciò giova anche alle performance in single thread dove i carichi di lavoro non possono essere divisi come con le DX12 o Vulkan, aumentando quindi le prestazioni coi titoli DX11.
Tali miglioramenti portano ad un aumento delle performance clock per clock di circa il 15% rispetto alla R9 390, e questo senza considerare le frequenze operative superiori rispetto a quest’ultima, grazie ovviamente al passaggio ai 14 nm.
Un’altra aggiunta è quella che AMD chiama “Shader Intrinsic Functions”. Esse derivano direttamente dall’esperienza di AMD col mercato console, e sebbene non abbiano molto a che fare con l’architettura Polaris di per sé, le SIF potrebbero avere un impatto drastico sul futuro delle GPU Radeon. Queste estensioni sono essenzialmente trasportate in toto dalle console tramite una libreria API tramite GPUOpen, possono essere “ported” facilmente nel mondo dei PC e possono garantire agli sviluppatori performance superiori grazie alla familiarità con architetture simili.






Discussione su post