
Se avete letto fin qui, dovrebbe essere evidente che Polaris è molto più che un’ulteriore evoluzione per l’architettura GCN di AMD. Invece, essa rappresenta un enorme incremento di efficienza delle pipeline che consentono all’attuale e alla prossima generazione di velocizzare i carichi di lavoro. Comunque, ciò che abbiamo descritto nella pagina precedente era solo la punta dell’iceberg.

Come avrete notato nelle settimane scorse, AMD ha sempre paragonato Polaris 10 alle R9 290 e 390, sia da un punto di vista prestazionale che architetturale. Laddove Polaris differisce dalle precedenti generazioni è il fatto che uno dei principi operativi di base è “fai di più con meno”. Ciò è evidente nella quantità di ROP, Shaders e Texture Units; ce ne sono meno di quante ce n’erano precedentemente, eppure sulla carta la RX 480 è destinata a batterle sia in efficienza che potenza.
Tale fenomeno è presente anche sul fronte degli ACE (Asynchronous Compute Engines), visto che ne troviamo solo 4 invece di 8 come in Hawaii, ma in realtà dovrebbe esserci un miglioramento nella capacità dell’architettura di processare carichi di lavoro asincroni. Invece di una completa allocazione di ACE, 2 di essi sono stati sostituiti da Schedulers Hardware dedicati. Questi schedulers hanno l’abilità di impegnare una percentuale o intere CU per diversi scopi in modo del tutto dinamico.
Questa, è la chiave per una corretta gestione temporale e spaziale delle risorse, per la pianificazione di operazioni concorrenti o processi in calcolo asincrono e, forse più importante, per il bilanciamento dinamico del carico tra le varie unità di calcolo. Potete immaginare questi nuovi ACE come Compute Engine “sotto steroidi”, non tanto per la maggior potenza a disposizione quanto più per l’infinita dinamicità con cui gestisce carichi di natura diversa.
Tutto ciò può sembrare un po’ complicato, ma il risultato è un significativo aumento delle performance in contesti asincroni e può anche aumentare la granularità con cui le CU possono essere controllate. Con un hardware Scheduler, un’intera CU o anche una determinata percentuale di ogni CU può essere dedicata ad un compito specifico e scalata proporzionalmente in modo totalmente dinamico.
Per esempio, gli HWS possono utilizzare l’accelerazione TrueAudio Next (che è ora utilizzata per l’audio posizionale in applicazioni VR) su un gruppo di SIMD o un’intera CU a seconda delle risorse richieste da un’applicazione specifica. In parole povere, significa che una porzione minore della GPU starà ferma a fare niente e in questo modo aumenteranno le prestazioni.
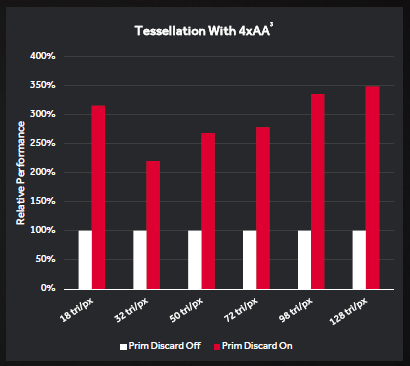
Un’altra aggiunta interessante è quella che AMD chiama il Primitive Discard Accelerator. Questa nuova funzione permette ai Geometry Engine di analizzare la geometria di una particolare scena e scartare texture e “triangoli” non necessari, il tutto all’inizio della pipeline.
In pratica, quando il PDA è utilizzato correttamente la GPU non sprecherà risorse renderizzando elementi che non verranno visti dal giocatore. Ciò è particolarmente importante con l’utilizzo dell’AA multi-sampling o qualsiasi anti-aliasing che richiede più passaggi e quindi, i guadagni prestazionali sono maggiori quanto più è elevato il livello di AA utilizzato.
C’è anche una nuova Index Cache che agisce come un punto d’accesso rapido per istruzioni geometriche più piccole. Essenzialmente, questa cache limita la quantità di informazioni che si spostano da una pipeline all’altra, liberando bandwidth interna. Combinata con il PDA, Polaris 10 può offrire, teoricamente fino a 3.5 volte le prestazioni della precedente generazione.
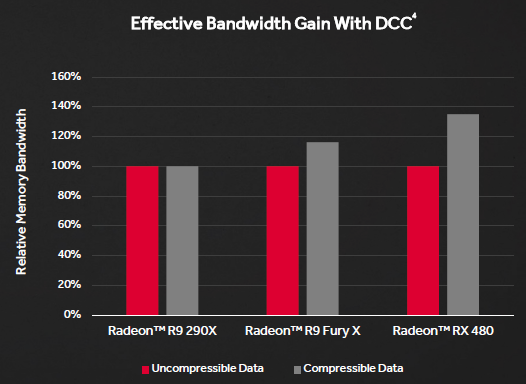
Sebbene le GDDR5 non possano offrire i benefici di banda delle HBM o le GDDR5, AMD ha comunque trovato un modo per aumentare il throughput senza adattare l’architettura ad uno standard di memorie più costoso. Senza nemmeno aumentare l’ampiezza del bus (occupando così un’area maggiore e, quindi, generando più calore), l’unico passo da fare è stato quello di migliorare gli algoritmi di compressione colore, nel tentativo di aumentare l’efficienza piuttosto che semplicemente alzare la banda massima teorica.
Già le precedenti architetture (Fiji e Tonga, soprattutto) includevano una sorta di color compression, ma Polaris alza l’asticella vantando supporto nativo per rapporti di compressione di 2:1, 4:1 e 8:1.
Sebbene il Radeon Technology Group ammetta formalmente che c’è ancora tanta strada da fare per arrivare ai livelli del DCC di NVIDIA, Polaris rappresenta un enorme passo in avanti nel colmare il gap tra le due aziende sotto questo punto di vista.
Allo stato attuale, infatti, gli algoritmi di DCC di AMD permettono ad un bus relativamente ridotto di 256 bit di avere prestazioni molto vicine a quello da 512 di precedente generazione.
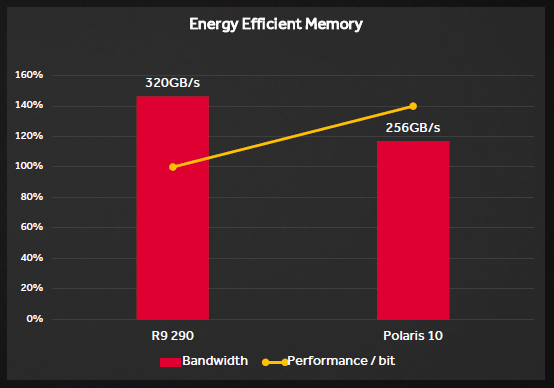
Insieme all’enormemente migliorata gerarchia di caching L2 e ai nuovi algoritmi migliorati di DCC, l’interfaccia di memoria di Polaris può non avere un enorme quantitativà di bandwidth, ma è estremamente efficiente. Presumibilmente, l’aumento di performance per bit è di circa il 40%, il che permette sia un risparmio energetico notevole che un miglior utilizzo delle risorse da parte degli sviluppatori.






Discussione su post