
3. Hawaii: architettura nei dettagli 

- 1. Introduzione: Sapphire

- 2. Sapphire Radeon R9-290X: specifiche tecniche
- 3. Hawaii: architettura nei dettagli
- 4. Hawaii: gestione dei clock dinamica
- 5. Hawaii: Eyefinity reinterpretato
- 6. Hawaii: TrueAudio, innovazione a 360°
- 7. Hawaii: Mantle, asso nella manica?
- 8. Galleria fotografica: la scheda nei dettagli
- 9. Configurazione di prova e metodologia di test
- 10. Test sintetici: Unigine Heaven
- 11. Test sintetici: FutureMark 3DMark11
- 12. Test sintetici: FutureMark 3DMark
- 13. Test sintetici: 3DMark Fire Strike Extreme
- 14. Test sintetici: AllBenchmark CatZilla
- 15. Test sui giochi: Thief (2014)
- 16. Test sui giochi: Bioshock Infinite
- 17. Test sui giochi: Batman: Arkham Origins
- 18. Test sui giochi: Metro Last Light
- 19. Test sui giochi: Tomb Raider (2013)
- 20. Test: overclock ed overvolt
- 21. Considerazioni finali
Potremmo assimilare l’architettura utilizzata dalla GPU Hawaii (XT e Pro) in un GCN 1.1, come viene definito da AMD stessa. La potenza per mm2 è del 5% maggiore rispetto alla precedente generazione (ovvero quella su cui si basano le VGA HD7000). Per capirci, le soluzioni tecniche sono le stesse adottate dalla GPU HD7790 (recensita da noi QUI), ovviamente portando il tutto in grande scala viste le dimensioni mastodontiche del chip utilizzato sulla 290X/290: si parla di ben 6,2 miliardi di transistors in un package di 438mm2, con un aumento del ben 24% rispetto alla precedente generazione. nVidia, con il suo GK110, arriva ad addirittura 7.1 miliardi, ma con una superficie ben superiore. La densità di transistors è, pertanto, di gran lunga superiore. Andiamo quindi ad analizzare nel dettaglio l’architettura della scheda:
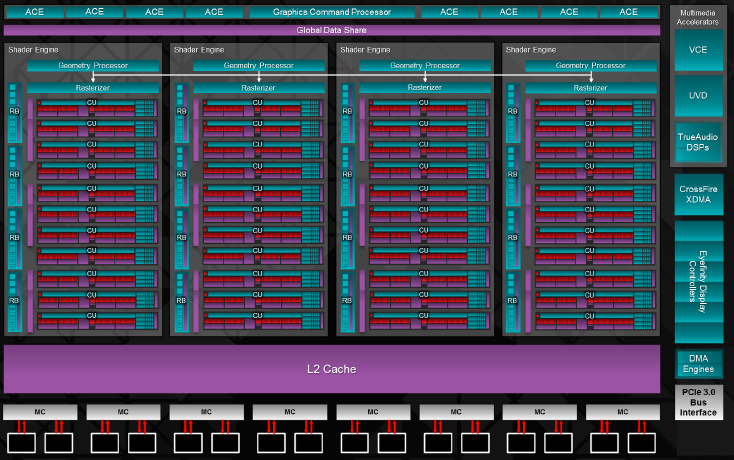
Parlando ad alto livello la scheda presenta un aumento negli Stream Processors di ben 768 unità, un aumento della Cache L2, insieme all’introduzione di nuovi componenti. Sul die della GPU, infatti, è integrato anche il nuovo DSP TrueAudio responsabile della gestione audio nei videogames, ma di questo parleremo in una delle prossime pagine. Troviamo i nuovi motori xDMA che gestiscono il CrossFireX di tipo “bridgeless” (ovvero senza la necessità di utilizzare un ponte esterno per collegare le schede), insieme ai nuovi motori di gestione EyeFinity che consentono di pilotare navitamente 6 schermi con una sola scheda, in configurazione 3×2. È facile intendere che non ci troviamo di fronte ad un’architettura totalmente nuova; piuttosto, ci troviamo di fronte ad un “refresh” della già molto efficiente GCN, con una riorganizzazione dello spazio sul die, grazie al quale è stato possibile inserire un bus da 512 Bit occupando meno spazio del bus da 384 Bit di Tahiti XT, il tutto senza perdere prestazioni, grazie a 8 collegamenti da 64 Bit ad alta efficienza.
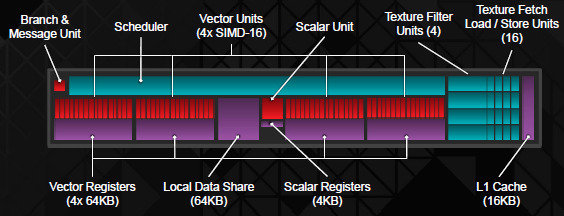
La Compute Unit (CU) di Hawaii si presenta uguale a quella di Tahiti, che fa dell’elevata efficienza di calcolo rispetto allo spazio occupato il suo punto di forza. Al pari di Tahiti, infatti, ogni CU può gestire calcoli in maniera autonoma rispetto alle altre, ottimizzando quindi la parallelizzazione nei calcoli disegnati per tale tipo di computing. Dalla prospettiva del thread processing, ogni CU dispone di 4 sub unità vettoriali (denominate SIMD) composte ognuna da 16 Stream Processors, per un totale di 64 SP per CU. Questo schema è supportato da 4 Texture Units e 16KB di cache L1 a lettura e scrittura esclusiva della CU. Insieme ad ogni unità vettoriale (VU) indipendente, AMD ha associato uno scheduler ad alto bandwidth, che lavora insieme alla cache unificata (di L2) e alla cache dedicata ad ogni CU, facilitando la condivisione dei dati attraverso le linee dati. In soldoni, esso funge da semaforo indirizzando correttamente i flussi dati. Un’altra parte importante nella gerarchia delle CU è la presenza di unità scalari (SU) con registri dedicati. Questa sub-unità funge da core programmabile di tipo general purpose, facendosi carico di una parte dei calcoli di alcune aree delle CU, o lavorando indipendentemente se necessario, come se fosse un vero e proprio processore associato ad ogni CU. Nessuno di questi moduli è stato cambiato da Tahiti, tuttavia è stata migliorata ulteriormente l’efficienza in caso di calcoli logaritmici o esponenziali di tipo 1ULP, ovvero quando si compiono operazioni in FP. Hawaii porta con sé il supporto al MQSAD (masked quad sum of absolute difference) e Shaders compatibili con lo standard IEEE-2008, insieme ad una serie di cambiamenti nella queue di processi:
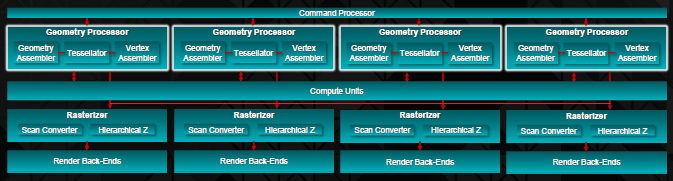
La stragrande maggioranza di miglioramenti è stata implementata negli stadi di processing della geometria, requisito necessario per supportare e calcolare correttamente i set di istruzioni contenuti nelle DX11.2 e nelle Direct3D 11.2. Al posto dei due Geometry Engine, ora ci sono ben quattro GE, consentendo di gestire 4 primitive concorrenti ad ogni ciclo di clock. Questa novità è gestita senza problemi grazie alle capacità di caching maggiorate (in particolar modo, la cache di L2 R/W è stata aumentata a 1MB, con ben 1TB/s di banda passante per le comunicazioni tra le cache di L1 e L2). Ulteriori miglioramenti sono stati applicati on-die, grazie ad un front-end di caricamento e salvataggio incrementato, il quale è utilizzato per velocizzare le comunicazioni tra le varie unità di calcolo e la memoria. AMD, finalmente, ha migliorato con questo meccanismo il buffering tra GPU e memorie, consentendo così di aumentare il throughput di tassellazione, cosa che era il punto debole della precedente architettura.

Ogni CU, Geometry Processor e Rasterizzatore, insieme a 4 Back-End di renderizzazione individuali, insieme ad altri elementi secondari, sono combinati in un’unica unità organizazzionale denominata Shader Engine. Ogni Shader Engine dispone di 704 SP (divisi in CU di 64 SP ciascuna), 44 Texture Units e 16 Rop. Lo Shader Engine, per intenderci, è paragonabile al Graphics Compute Unit di nVidia, con la differenza che AMD ha aggiunto RB (Rendering Back-Ends) indipendenti dalla gerarchia delle memorie. Con questa riorganizzazione, AMD ha raccolto le risorse in questi engine in modo da facilitare le comunicazioni inter-cores. Per esempio, mentre tutte le cache degli engine possono essere condivise da 4 Compute Engines ciascuna, parallelamente gli RB sono configurabili in modo da assistere suddetti CE o in modo da gestire calcoli del tutto indipendenti e scollegati.
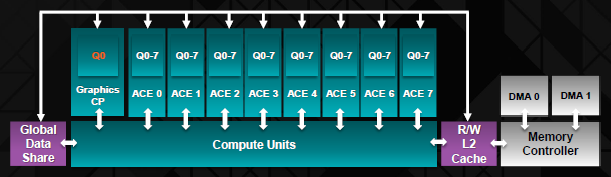
Il throughput di calcolo, inoltre, è stato indirizzato tramite 8 ACE (Asynchronous Compute Engines, Motori di Calcolo Asincroni) al posto dei 2 di Tahiti. Non solo hanno accesso diretto alla Cache L2 e ai Data Stream gestiti da tutte le unità di calcolo, ma possono anche gestire 8 code di calcolo. Prima di passare per gli engine DMA, i dati elaborati dagli ACE passa per il memory controller. In particolare, i motori DMA sono in grado di saturare il bus bidirezionale di uno slot PCI-E 16x di tipo 3.0, tuttavia le prestazioni computazionali di questa particolare architettura non giungeranno mai a richiedere tutta quella banda passante, in quanto la maggioranza dei calcoli viene effettuata direttamente dalla GPU.
3. Hawaii: architettura nei dettagli
- 1. Introduzione: Sapphire
- 2. Sapphire Radeon R9-290X: specifiche tecniche
- 3. Hawaii: architettura nei dettagli
- 4. Hawaii: gestione dei clock dinamica
- 5. Hawaii: Eyefinity reinterpretato
- 6. Hawaii: TrueAudio, innovazione a 360°
- 7. Hawaii: Mantle, asso nella manica?
- 8. Galleria fotografica: la scheda nei dettagli
- 9. Configurazione di prova e metodologia di test
- 10. Test sintetici: Unigine Heaven
- 11. Test sintetici: FutureMark 3DMark11
- 12. Test sintetici: FutureMark 3DMark
- 13. Test sintetici: 3DMark Fire Strike Extreme
- 14. Test sintetici: AllBenchmark CatZilla
- 15. Test sui giochi: Thief (2014)
- 16. Test sui giochi: Bioshock Infinite
- 17. Test sui giochi: Batman: Arkham Origins
- 18. Test sui giochi: Metro Last Light
- 19. Test sui giochi: Tomb Raider (2013)
- 20. Test: overclock ed overvolt
- 21. Considerazioni finali






Discussione su post