
Ne avevamo già parlato ma nessuno ci credeva, invece arrivano i primi benchmark della combinazione degli eterni rivali: Radeon e GeForce. Se fino ad oggi c’è stata la guerra tra fanboys, da oggi si potranno non solo deporre le armi, ma collaborare nella maniera più stretta mai vista.
Come già accennato precedentemente, le DirectX 12 sono delle API a bassissimo livello, come i MANTLE per intenderci, e cioè con pochi rimbalzi di informazioni che consentono alle nostre macchine di utilizzare al meglio l’hardware, senza perdere tempo in vane comunicazioni tra i componenti. Si parla infatti di un pool d’elaborazione, che per spiegarlo a chi non fosse addetto ai lavori, è possibile immaginarne il funzionamento come una vera e propria piscina di calcolo, dove i dati arrivano a flusso continuo per essere elaborati “da chi è disponibile”, utilizzando anche gli stessi componenti per effettuare calcoli diversi. E, come non bastasse, l’utilizzo dei cores della CPU è decisamente migliorato: stando alle statistiche, c’è una evidente differenza prestazionale sino a 6 core (contro i 2-3 dei DX11), processo estremamente utile per gli sviluppatori di giochi, sopratutto dal momento che il collo di bottiglia derivante dalla CPU è tra i più grandi ostacoli che affrontano le GPU oggi.
Se prima si era obbligati alla scelta, spetta ora agli sviluppatori decidere se vogliono usare più GPU e come vogliono usarle. Questo ci porta all’articolo di oggi, uno sguardo iniziale verso le capacità multi-GPU con l’esempio di Oxide Games che ha usato il motore Nitrous con le nuove DirectX 12 e il gioco in uscita (momentaneamente presente su Steam Early Access) Ashes of the Singularity.
A differenza delle varie tecnologie ibride che sono arrivate ai giorni nostri (dai drivers combinati alle Hydra), Microsoft è riuscita a far comunicare le varie GPU tra loro con 3 metodi principali, tra i quali troviamo Implicit Multi-Adapter (IMA), Explicit Multi-Adapter (EMA) e, ovviamente , il PostProcessing.
Il metodo più semplice è l’IMA, è sicuramente quello con meno problemi di rendering ma è anche quello che utilizza meno le potenzialità delle GPU, modello simile come gestione al sistema multiGPU presente nei DX11 in quanto com l’IMA, la gran parte del carico di lavoro è lasciato ai drivers (quindi, parlando in soldoni, ad AMD e Nvidia che dubitiamo fortemente accettino di collaborare in questi termini).

L’EMA invece, è una tecnologia molto più avanzata che non ha assolutamente le limitazioni viste nell’IMA, ma ha dei problemi sicuri e sinceri. Le problematiche principali sono che anche questo modello comportamentale delle GPU richiede, seppur minimamente, un controllo da parte dei drivers, e trattandosi di GPU high End, non tutti saranno disposti ad implementarli dato che i sistemi con multi GPU high end sono una piccola frazione del mercato PC gaming. Tuttavia, sono la via migliore da percorrere in quanto queste modalità delegano agli sviluppatori di giochi il programma per il funzionamento multi-GPU, specificando come il carico lavoro sarà assegnato a ogni GPU, come verrà assegnata la memoria, come comunicheranno le GPU. Dando agli sviluppatori un controllo esplicito su tutto il processo, hanno migliori possibilità di estrarre le prestazioni su un sistema multi-GPU, in quanto hanno il controllo quasi assoluto sia dell’API che del il gioco, permettendo loro di lavorare con più controllo e più informazioni di un qualsiasi precedente metodo multi-GPU. Il problema in questo caso è che ci vuole molto meno lavoro da parte degli sviluppatori per far funzionare i giochi in multiGPU (che è un bene) ma poi ci vuole un grosso lavoro di ottimizzazione per far si che il tutto lavori bene. Gli EMA possono lavorare in due modalità: con GPU disgiunte (unlinked GPUs) o unite (linked GPUs).

Il primo metodo detto Unlinked GPUs offre la maggior parte delle caratteristiche di EMA ed il fine è quello di permettere agli sviluppatori di sfruttare appieno tutte le risorse della GPU di un sistema, sempre che ce ne siano disposti a fare tutto il lavoro necessario per gestire tali risorse. Al contrario di modalità linked ed IMA, questa modalità può lavorare con GPU (purchè compatibili con DX12) di qualsiasi marchio, fornendo quel tanto che basta per consentire lo scambio di dati tra le GPU e mettendo tutto il resto nelle mani dello sviluppatore. In questo modo potremo sfruttare due GPU diverse, che esse siano GPU discrete o iGPU.
L’EMA permette agli sviluppatori di scambiare dati tra le GPU, andando oltre il semplice calcolo completo, permettendo scambio di immagini in rendering e di scambio frames renderizzati parzialmente, buffers, e altri tipi di dati. Questi fattori sono quelli che portano in tavola la potenza e la flessibilità dell’EMA, che usa il potenziale di più GPU che lavorano insieme, siano esse simili o diverse; né più né meno.
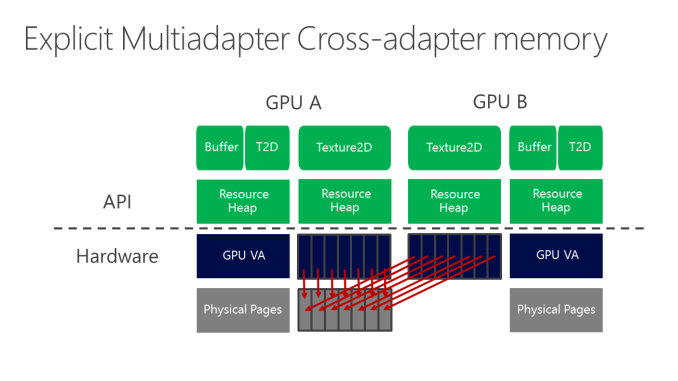
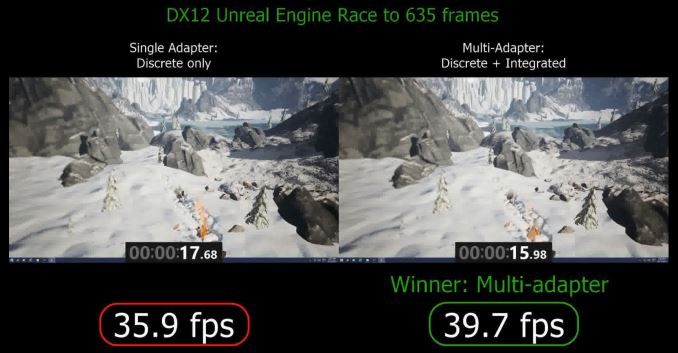
Tuttavia, le GPU possono lavorare insieme ma dovranno farlo in maniera intelligente: altrimenti, dopo aver tolto il collo di bottiglia della CPU, sarà lo stesso BUS PCI a diventare un bottle-neck, e questo perchè rispetto alla memoria on-board, tutte le operazioni che si svolgono su PCI Express sono relativamente lente e ad alta latenza; ecco perchè le GPU non riusciamo ancora a farle parlare ad una certa velocità (ed ecco perchè per CFX e SLI si usa spesso il bridge). Sopratutto, questa metodologia è utile perchè la maggior parte dei PC, oltre ad una scheda video discreta, possiede una iGPU che rimane dormiente, ma che può essere ben sfruttata grazie ai DX12: ovviamente rispetto ad una dGPU da 200€, una iGPU offre una frazione delle prestazioni, ma è anche una risorsa GPU che sta andando inutilizzata e che può fare la differenza tra appena giocabile e ben giocabile (immaginiamo un gioco che passi da 28 a 34-35fps), come nell’esempio qua sotto:
Venendo alla modalità Linked di EMA, possiamo dire che questa modalità offra -almeno in potenza- prestazioni superiori, ma che sia davvero molto più difficile da gestire: è nel complesso l’equivalente di SLI/CrossFire per EMA, ed è progettato per i sistemi in cui tutte le GPU in uso sono quasi identiche, ma col vantaggio da utilizzarle come una sola GPU non andando a perdere parte dei processori e delle memorie disponibili. La nuova API insomma, fornisce una vasta gamma di funzionalità -con un po’ di limitazioni hardware derivanti da quanto velocemente le GPU possono scambiare dati- ma a differenza di DirectX 11 e IMA, sono gli sviluppatori che definiscono come le GPU dovrebbero lavorare insieme.
Vai alla pagina successiva: “Un po’ di test”.
Un po’ di test. –>
Anandtech riposta i primi benchmark di Ashes of Singularity nelle varie modalità, e noi li riportiamo per voi, e iniziamo dalla configurazione utilizzata:
| CPU: | Intel Core i7-4960X @ 4.2GHz |
| Motherboard: | ASRock Fatal1ty X79 Professional |
| Power Supply: | Corsair AX1200i |
| Hard Disk: | Samsung SSD 840 EVO (750GB) |
| Memory: | G.Skill RipjawZ DDR3-1866 4 x 8GB (9-10-9-26) |
| Case: | NZXT Phantom 630 Windowed Edition |
| Monitor: | Asus PQ321 |
| Video Cards: | AMD Radeon R9 Fury X ASUS STRIX R9 Fury AMD Radeon HD 7970 NVIDIA GeForce GTX Titan X NVIDIA GeForce GTX 980 Ti NVIDIA GeForce GTX 680 |
| Video Drivers: | NVIDIA Release 355.98 NVIDIA Release 358.50 AMD Catalyst 15.8 Beta AMD Catalyst 15.10 Beta |
| OS: | Windows 10 Pro |
Queste registrazioni sono state effettuate utilizzando la GeForce GTX 980 e la Radeon R9 Fury X e sostituendo la scheda video primaria e secondaria (in modo da avere o Radeon o GTX come scheda primaria e l’altra di ausilio). Entrambi i video sono registrati a risoluzione 2560×1440 e con il v-sync attivato, anche se i limiti di YouTube sono 60FPS e 1080p in questo momento.
Nel complesso si fa fatica a trovare una differenza netta tra i due video. Non importa quale GPU sia primaria, entrambe le configurazioni funzionano correttamente e senza alcun problema, mostrando che le DirectX 12 in EMA funzionano come previsto.
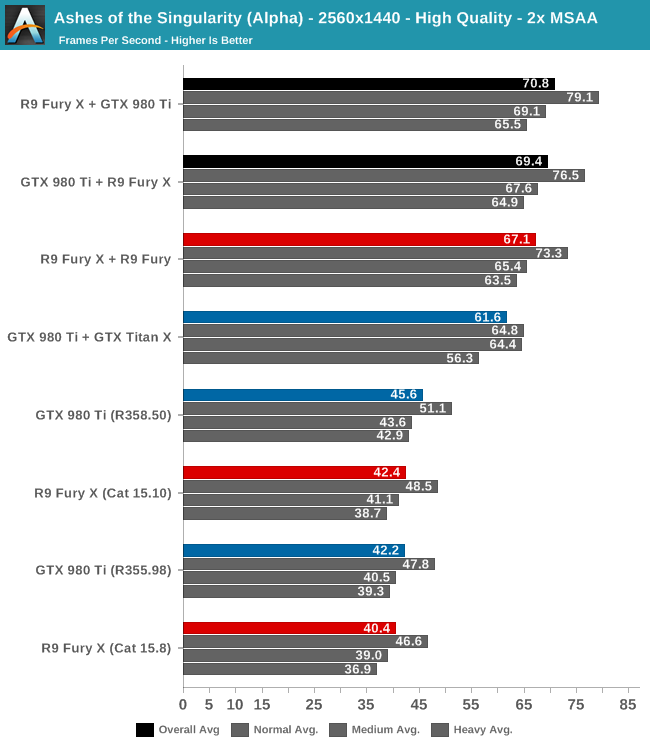
Ci credereste che le configurazioni GPU miste sono più veloci delle configurazioni omogenee? I risultati dei setup sono abbastanza sorprendenti, con i setup misti che vanno più rapidamente di quelli omogenei: il setup R9 Fury X + R9 Fury è il più forte tra gli omogenei, e più lento ancora è quello con la GTX 980 Ti + GTX Titan X, che in media solo 61.6fps. I gruppi misti invece, vincono sempre e di parecchio. Non si sa poi bene per quale motivo, ma se il gioco viene diretto dalle GTX è più lento, mentre se la scheda principale sia una Radeon, la GTX lavorerà molto meglio dando una mano più sostanziale.
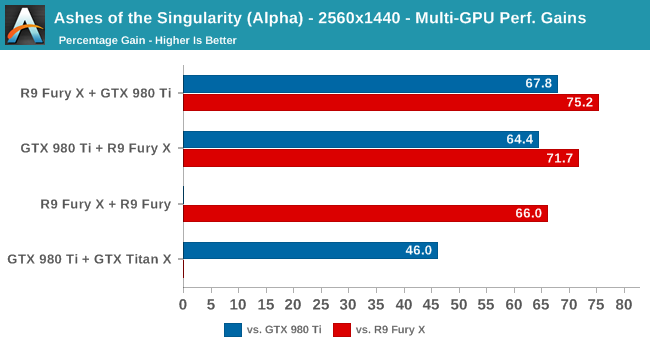
Nel secondo grafico vediamo la percentuale di guadagno prestazioni rispetto alle singole GTX 980 ti (in blu) e Fury X (in rosso). Anche qui vengono confermati i dati: i gruppi misti funzionano meglio, e ancora meglio se la direttrice è una Radeon accompagnata da una GTX. A risoluzioni ancora maggiori, il risultato non cambia, anzi nei gruppi misti la Radeon dominante stacca la GTX dominante di un 15% buono, essendo comunque i misti molto sopra i gruppi omogenei: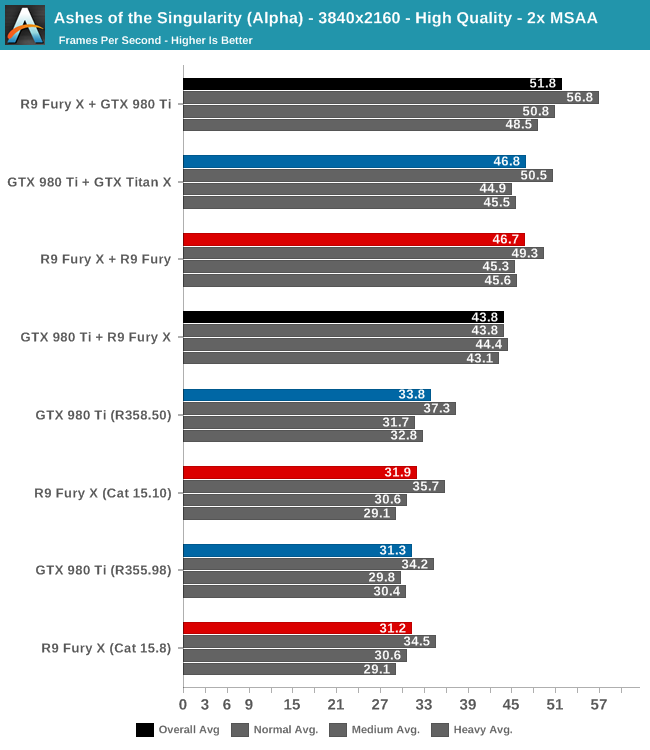
E la solfa rimane identica con GPU più datate ma ancora valide: Radeon dominante in testa, con un aiuto formidabile della GTX:
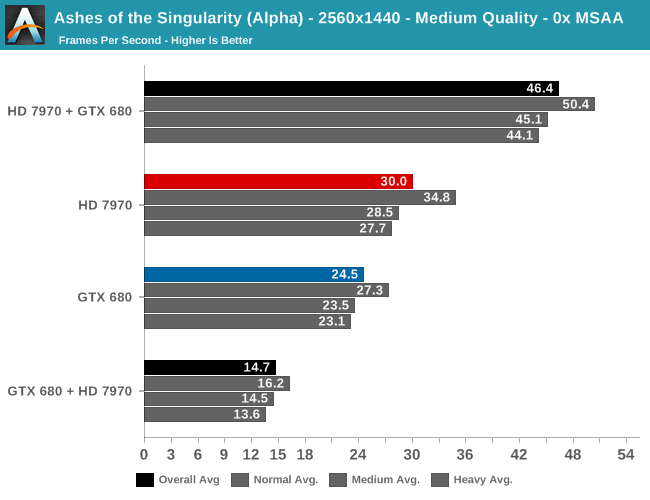
Emerge che le architetture delle GPU si siano venute parecchio incontro negli anni, e che con l’EMA, Microsoft e ifornitori di GPU abbiano stabilito un percorso solido per consentire gli sviluppatori di giochi di sfruttare finalmente le prestazioni di più GPU in un sistema, sia con GPU integrata che discreta. Sottolineiamo però che quello che succede da qui è in definitiva più nelle mani degli sviluppatori di giochi che gli sviluppatori di hardware e che questi ultimi avranno un evidente interesse a promuovere e sviluppare la tecnologia multi-GPU, al fine di vendere più GPU.
Speriamo che la tecnologia vada ancora migliorandosi, e speriamo di avere preziose news a riguardo quanto prima! Stay Tuned with ReHWolution!




Discussione su post