
Fin da Fermi, ogni architettura di NVIDIA ha avuto qualche sorta di delta color compression di tipo lossless per ottimizzare la bandwidth di memoria. I benefici della compressione sono molteplici: riduce l’ammontare di informazioni trasferite tra i client on-die (TMU, Frame Buffer), semplifica l’utilizzo della cache L2 e minimizza quanti dati vengono scritti nella memoria.

Mentre Maxwell ha sorpassato il suo predecessore con un rapporto di compressione di 2:1, Pascal va persino oltre. NVIDIA ha pensato bene non solo di aumentare la bandwidth con le GDDR5X ma anche di migliorare le ottimizzazioni integrate nell’architettura.
Pascal, ancora una volta, ha un rapporto di compressione di 2:1, ma nel caso i giochi lo supportino, ci sono due rapporti di compressioni ulteriori (4:1 e 8:1) che migliorano ulteriormente la situazione.
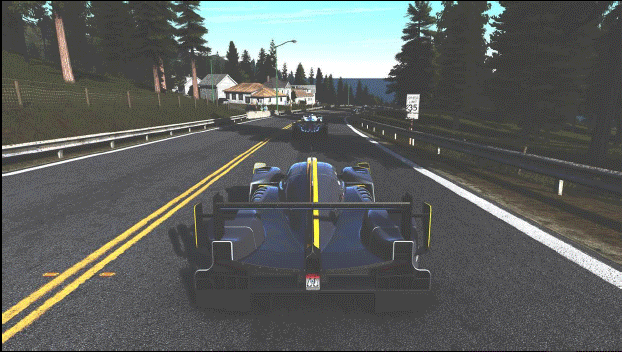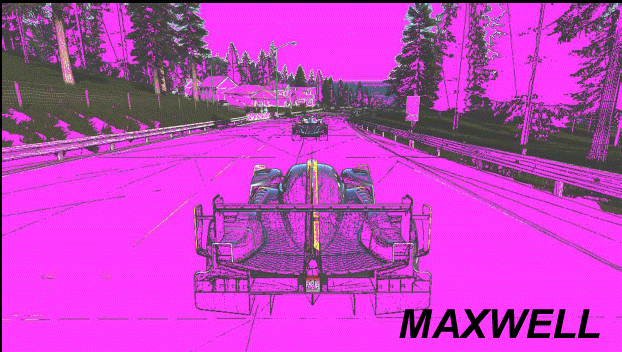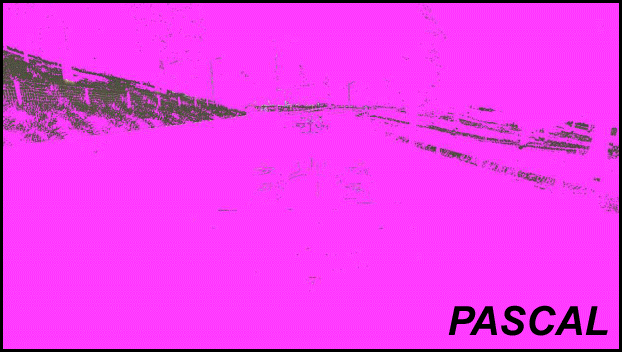
Nell’esempio qui sopra, Project Cars è utilizzato per dimostrare come Maxwell era efficiente nel comprimere molto della scena (le aree in viola), i nuovi algoritmi di Pascal portano le cose al livello successivo senza compromettere la qualità dell’immagine.
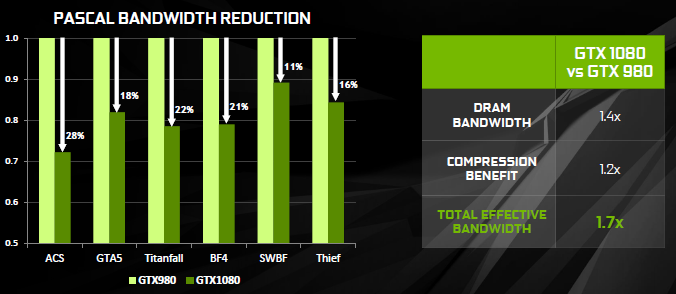
Combinata con la bandwidth addizionale garantita dalle memorie G5X, l’efficienza totale della bandwidth della GTX 1080 è praticamente duplicata rispetto alla generazione precedente. Più importante, gli algoritmi di compressione colore permettono di ridurre la quantità netta di bandwidth richiesta dai giochi, lasciando più spazio a situazioni inaspettate e persino a workload di calcolo.
Pascal: Async Computing rielaborato
Con le DX12 all’orizzonte una delle maggiori critiche contro Maxwell erano le performance scadenti in alcune situazioni che richiedessero alla GPU workloads multipli indipendenti (o asincroni). Cose come la fisica, l’audio, l’AI, la VR e il post processing possono essere considerate tra essi. Nonostante avesse schedulers di tipo hardware (NVIDIA non utilizzava una soluzione software-oriented), essi non erano particolarmente efficienti in alcuni scenari chiavi, come evidenziato dai workload compute+graphics presenti in Ashes of the Singularity. Non è solo questo gioco, comunque, ad aver preoccupato NVIDIA, visto che le DX12 spingono gli sviluppatori ad utilizzare la natura altamente parallela delle GPU, permettendo loro di raggiungere boost prestazionali quando processi asincroni sono propriamente implementati.
Pascal cambia le cose in svariati modi. Innanzitutto, gli scheduler hardware sono stati aggiornati in modo da reindirizzare le richieste ad una velocità maggiore. Essi inoltre hanno una certa quantità di “Forward Branch Prediction” (previsione del prossimo calcolo, in pratica) integrata nel loro framework, in modo che ogni volta che le risorse on-die sono disponibili, ci siano dati inseriti nella pipeline.
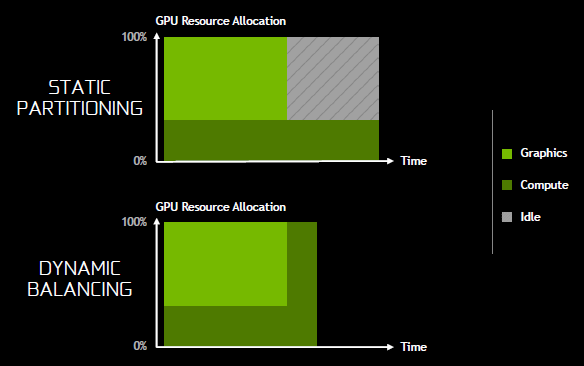
Un’altra feature aggiunta è il Dynamic Load Balancing. Con il partizionamento statico delle GPU di Maxwell, i workload grafici e di calcolo erano eseguiti su partizioni dedicate separate. Tuttavia, entrambi i workloads dovevano essere completati allo stesso tempo per rendere questo metodo efficiente, altrimenti se uno dei due avesse finito prima, una porzione della GPU avrebbe “preso polvere”. Questi cicli di inattività si sarebbero accumulati per poi negare qualsiasi beneficio in performance derivante dall’eseguire operazioni in parallelo. Il DLB hardware-based di Pascal ingaggia ulteriormente questi scheduler in modo da avere un approccio ibrido al bilanciamento del carico. In questo modo tali partizioni possono essere utilizzate dinamicamente sia per workloads grafici che di calcolo, eliminando inattività e migliorando le prestazioni.
Eseguire operazioni in asincrono va ben oltre il partizionamento, visto che in ognuna di queste situazioni finora descritte ci sono migliaia, milioni di operazioni e workload in esecuzione, alcuni dei quali più critici di altri. In realtà determinare quali sono prioritari e hanno bisogno di essere eseguiti più velocemente è particolarmente difficoltoso. NVIDIA ha dato un buon esempio sulla cosa durante i briefing affermando che potrebbe un’operazione asincrona che talvolta è richiesta per far sì che riparta una scansione o che un frame venga generato.
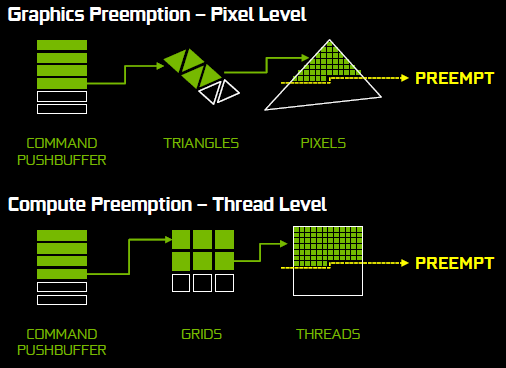
Una volta completata la “preemption” ad alto livello nella pipeline grafica, c’era la possibilità di creare un overflow ai livelli inferiori di calcolo. Per riconoscere, razionalizzare e dare priorità ai pacchetti dati e di operazioni, NVIDIA ha implementato diversi livelli di preemption. Pixel Level Preemption è una novità per le GPU moderne e permette ad ogni GPC di registrare i progressi in un determinato compito, così che se una previsione è richiesta, essa può salvare le context information, processare le info critiche e ripartire dal punto in cui il compito precedente era stato interrotto. Tutto ciò, in tempi pari a 100 microsecondi.
Anche la Compute Preemption è stata aggiunta e funziona in modo simile alla PLP, ma invece di agire sui singoli pixel, essa agisce sui workloads a livello di processo. Combinata con la PLP, questa feature permette a Pascal di cambiare tipo di workload ad una velocità ridicolmente elevata ed aumentare le prestazioni in situazioni dove l’adattabilità parallela asincrona è richiesta.
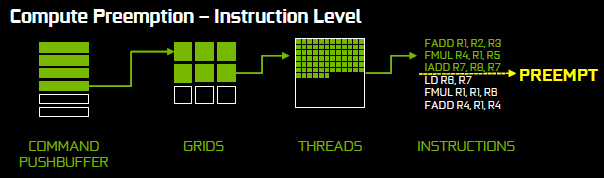
In aggiunta alla tradizionale Compute Preemption eseguita a livello di thread, Pascal aggiunge un altro filo alla matassa essendo la prima architettura a implementare un Instruction Level Preemption nel Compute Preemption. Sebbene essa possa essere utilizzata solo per compiti basati su CUDA, come PhysX, VR e altri miglioramenti GameWorks, i suoi benefici sono ben maggiori. NVIDIA la mette così: in questa modalità di operazione, quando una richiesta di preemption viene ricevuta, tutti i calcoli dei processi si interrompono all’istruzione corrente e lo stato viene cambiato immediatamente. Tale modalità coinvolge sostanzialmente più informazioni sullo stato dei tasks, visto che tutti i registri di tutti i processi in esecuzione vanno salvati, ma questo è l’approccio più robusto per calcoli di tipo generico in esecuzione nella GPU.
Pascal: Simultaneous Multi Projection: una rivoluzione nel multimonitor
In un mondo di standard per display in continua evoluzione e modi diversi di mostrare agli spettatori “nuovi mondi”, i tradizionali display piatti vengono integrati da tecnologie più recenti che richiedono alcuni aggiornamenti nel modo in cui le GPU gestiscono i workloads.

Mentre molte architetture GPU moderne come Maxwell supportano cose come VR, AR, surround, pannelli curvi e altri scenari, il modo in cui gli algoritmi di rendering sono strutturati causa svariate inefficienze. Questo si aggiunge ai frame times e potrebbe portare ad un esperienza non ottimale per gli utenti. In alcuni casi, questa semi-compatibilità potrebbe richiedere molteplici passaggi di rendering. o renderizzare più volte le stesse immagini, causando distorsioni o tearing, o entrambe le cose.

Pascal cambia questa equazione in maniera importante con l’aggiunta di un blocco funzionale Simultaneous Multi-Projection Engine nella struttura del PolyMorph Engine. Laddove Maxwell aveva capacità limitate nel multi-resolution che poteva portare a distorsioni delle direzioni di proiezione, l’SMP engine in Pascal può gestire individualmente la geometria richiesta per fino a 32 proiezioni concorrenti. Tutto ciò, senza overhead da parte dell’applicazione.
Una delle considerazioni chiave del design degli SMP Engine è stata il suo posizionamento nel tipico ambiente di workflow di Pascal. Visto che la sua funzionalità è posizionata subito dopo le pipeline geometriche l’applicazione esegue a questo stadio tutto il lavoro che altrimenti verrebbe eseguito a stadi superiori di elaborazione. In aggiunta, essendo basato su un motore completamente hardware, esso può duplicare gli stream di dati elaborati, visto che essi non lasciano mai la GPU, aumentando massivamente l’efficienza per i calcoli geometrici ad alto livello (come la tassellazione) in un ambiente di proiezioni.

In termini puramente pratici, l’engine che gestisce l’SMP può portare enormi miglioramenti nel campo della VR. In questi scenari, la GPU è forzata a processare 2 proiezioni concorrenti a bassa latenza verso gli occhi. In questo modo, ciò raddoppia la potenza elaborativa richiesta rispetto al solito, ma il nuovo blocco funzionale di Pascal può processare gli iniziali workload geometrici al doppio della velocità, avendo anche un effetto positivo sul rendering dei pixel.
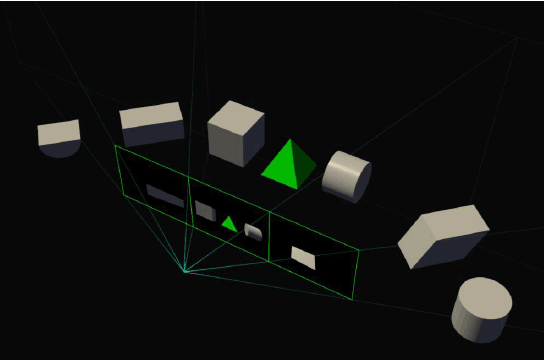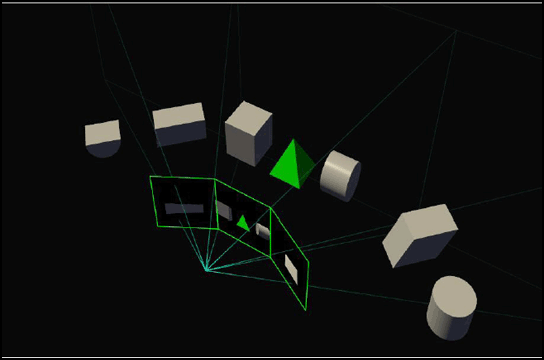
Un’applicazione pratica dell’SMP è il supporto ottimale per i sistemi surround. Di solito, i pannelli destro e sinistro sono leggermente inclinati, creando un ambiente completamente avvolgente, ma in ogni caso ciò causa image warping (distorsione dell’immagine). Il modo giusto di renderizzare su un display surround è attraverso una diversa proiezione per ognuno dei tre display, facendo corrispondere l’angolo del display ed eliminando l’effetto “fish-eye” a cui il surround è associato di solito.
L’engine SMP di Pascal può lavorare per l’eliminazione del problema specificando 3 proiezioni concorrenti ma separate, ognuna corrispondente ad un display orientato diversamente. Ora, sarete capaci di modificare completamente l’angolo in cui i motiro destro e sinistro visualizzano l’immagine e vedrete la grafica renderizzata in prospettiva geometricamente corretta, con un angolo di visuale maggiore. Detto ciò, un’applicazione che usa l’SMP deve supportare un FOV ampio, ed avere il supporto alle API dell’SMP in modo da attivare un FOV maggiore.
In soldoni, ciò significa che gli sviluppatori, oltre a supportare a livello driver tale impostazioni, dovranno implementare tale funzionalità nei propri giochi.






Discussione su post