
Introduzione: Sapphire Technology–>
Precisamente due anni fa (e qualche giorno) AMD annunciava che Sapphire, partner n°1 dell’azienda di Sunnyvale, sarebbe diventato l’unico distributore per le soluzioni professionali FirePro, lineup dell’azienda dedicata alle operazioni di computing in OpenCL.
![]()
Ancora oggi, la GPU più potente in ambito di computing in OpenCL, per AMD, è la Hawaii XT, la stessa utilizzata dalla R9 290X, ovviamente con i dovuti accorgimenti per l’ambiente server. Oggi, recensiamo il modello di punta della proposta FirePro, la W9100, caratterizzata da 2816 Stream Processors abbinati, tramite un bus a 512 bit, a ben 16GB di memoria GDDR5. Non mi resta che augurarvi buona lettura!
Sapphire AMD FirePro W9100: specifiche tecniche–>
Di seguito, la tabella delle specifiche tecniche della scheda video, ulteriori informazioni sono consultabili in versione integrale sul sito ufficiale del produttore (Sapphire):

Specifiche alla mano, ci troviamo di fronte ad un chip Hawaii XT con un quantitativo di RAM quadruplo rispetto alla versione “desktop”. 2816 Stream Processors, abbinati ad un bus da 512 bit e ben 16GB GDDR5 a 5000 MHz (1250 MHz quadruplicati). Perché tutta questa VRAM? Perché si parla di schede da heavy computing, dove quindi un buffer maggiorato serve ad effettuare ogni calcolo in tempo reale, senza andare in “buffering”.
La scheda, che presenta un TDP di 275W, porta con sé un design simile alla 290X reference, apportando però migliorie grazie ad una backplate e ad un dissipatore più lungo (anche la scheda è più lunga, raggiungendo ben 29 centimetri) che consentono di tenere a bada i ben 5.24 TFLOPS di potenza in Single Precision Floating Point e 2.62 TFLOPS in Double Precision Floating Point, mantenendo quindi un rapporto 1:2 tra le due potenze computazionali, a differenza del rapporto 1:8 mantenuto dalle Hawaii XT e 1:32 mantenuto dalle Fiji.
Hawaii: architettura nei dettagli–>

Potremmo assimilare l’architettura utilizzata dalla GPU Hawaii (XT e Pro) in un GCN 1.1, come viene definito da AMD stessa. La potenza per mm2 è del 5% maggiore rispetto alla precedente generazione (ovvero quella su cui si basano le VGA HD7000). Per capirci, le soluzioni tecniche sono le stesse adottate dalla GPU HD7790 (recensita da noi QUI), ovviamente portando il tutto in grande scala viste le dimensioni mastodontiche del chip utilizzato sulla 290X/290: si parla di ben 6,2 miliardi di transistors in un package di 438mm2, con un aumento del ben 24% rispetto alla precedente generazione. nVidia, con il suo GK110, arriva ad addirittura 7.1 miliardi, ma con una superficie ben superiore. La densità di transistors è, pertanto, di gran lunga superiore. Andiamo quindi ad analizzare nel dettaglio l’architettura della scheda:
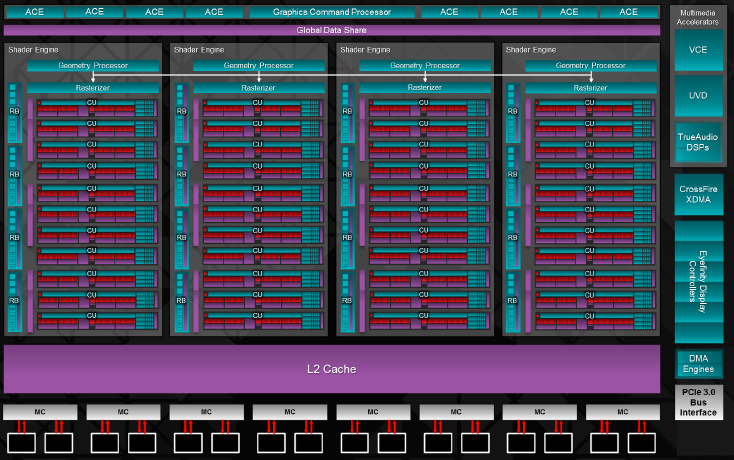
Parlando ad alto livello la scheda presenta un aumento negli Stream Processors di ben 768 unità, un aumento della Cache L2, insieme all’introduzione di nuovi componenti. Sul die della GPU, infatti, è integrato anche il nuovo DSP TrueAudio responsabile della gestione audio nei videogames, ma di questo parleremo in una delle prossime pagine. Troviamo i nuovi motori xDMA che gestiscono il CrossFireX di tipo “bridgeless” (ovvero senza la necessità di utilizzare un ponte esterno per collegare le schede), insieme ai nuovi motori di gestione EyeFinity che consentono di pilotare navitamente 6 schermi con una sola scheda, in configurazione 3×2. È facile intendere che non ci troviamo di fronte ad un’architettura totalmente nuova; piuttosto, ci troviamo di fronte ad un “refresh” della già molto efficiente GCN, con una riorganizzazione dello spazio sul die, grazie al quale è stato possibile inserire un bus da 512 Bit occupando meno spazio del bus da 384 Bit di Tahiti XT, il tutto senza perdere prestazioni, grazie a 8 collegamenti da 64 Bit ad alta efficienza.
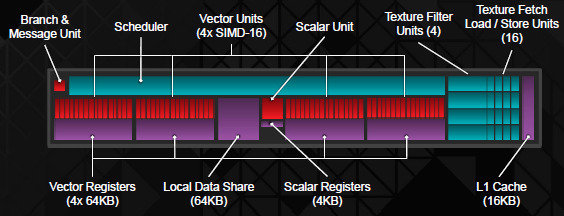
La Compute Unit (CU) di Hawaii si presenta uguale a quella di Tahiti, che fa dell’elevata efficienza di calcolo rispetto allo spazio occupato il suo punto di forza. Al pari di Tahiti, infatti, ogni CU può gestire calcoli in maniera autonoma rispetto alle altre, ottimizzando quindi la parallelizzazione nei calcoli disegnati per tale tipo di computing. Dalla prospettiva del thread processing, ogni CU dispone di 4 sub unità vettoriali (denominate SIMD) composte ognuna da 16 Stream Processors, per un totale di 64 SP per CU. Questo schema è supportato da 4 Texture Units e 16KB di cache L1 a lettura e scrittura esclusiva della CU. Insieme ad ogni unità vettoriale (VU) indipendente, AMD ha associato uno scheduler ad alto bandwidth, che lavora insieme alla cache unificata (di L2) e alla cache dedicata ad ogni CU, facilitando la condivisione dei dati attraverso le linee dati. In soldoni, esso funge da semaforo indirizzando correttamente i flussi dati. Un’altra parte importante nella gerarchia delle CU è la presenza di unità scalari (SU) con registri dedicati. Questa sub-unità funge da core programmabile di tipo general purpose, facendosi carico di una parte dei calcoli di alcune aree delle CU, o lavorando indipendentemente se necessario, come se fosse un vero e proprio processore associato ad ogni CU. Nessuno di questi moduli è stato cambiato da Tahiti, tuttavia è stata migliorata ulteriormente l’efficienza in caso di calcoli logaritmici o esponenziali di tipo 1ULP, ovvero quando si compiono operazioni in FP. Hawaii porta con sé il supporto al MQSAD (masked quad sum of absolute difference) e Shaders compatibili con lo standard IEEE-2008, insieme ad una serie di cambiamenti nella queue di processi:
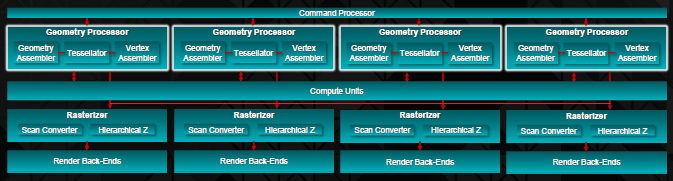
La stragrande maggioranza di miglioramenti è stata implementata negli stadi di processing della geometria, requisito necessario per supportare e calcolare correttamente i set di istruzioni contenuti nelle DX11.2 e nelle Direct3D 11.2. Al posto dei due Geometry Engine, ora ci sono ben quattro GE, consentendo di gestire 4 primitive concorrenti ad ogni ciclo di clock. Questa novità è gestita senza problemi grazie alle capacità di caching maggiorate (in particolar modo, la cache di L2 R/W è stata aumentata a 1MB, con ben 1TB/s di banda passante per le comunicazioni tra le cache di L1 e L2). Ulteriori miglioramenti sono stati applicati on-die, grazie ad un front-end di caricamento e salvataggio incrementato, il quale è utilizzato per velocizzare le comunicazioni tra le varie unità di calcolo e la memoria. AMD, finalmente, ha migliorato con questo meccanismo il buffering tra GPU e memorie, consentendo così di aumentare il throughput di tassellazione, cosa che era il punto debole della precedente architettura.

Ogni CU, Geometry Processor e Rasterizzatore, insieme a 4 Back-End di renderizzazione individuali, insieme ad altri elementi secondari, sono combinati in un’unica unità organizazzionale denominata Shader Engine. Ogni Shader Engine dispone di 704 SP (divisi in CU di 64 SP ciascuna), 44 Texture Units e 16 Rop. Lo Shader Engine, per intenderci, è paragonabile al Graphics Compute Unit di nVidia, con la differenza che AMD ha aggiunto RB (Rendering Back-Ends) indipendenti dalla gerarchia delle memorie. Con questa riorganizzazione, AMD ha raccolto le risorse in questi engine in modo da facilitare le comunicazioni inter-cores. Per esempio, mentre tutte le cache degli engine possono essere condivise da 4 Compute Engines ciascuna, parallelamente gli RB sono configurabili in modo da assistere suddetti CE o in modo da gestire calcoli del tutto indipendenti e scollegati.
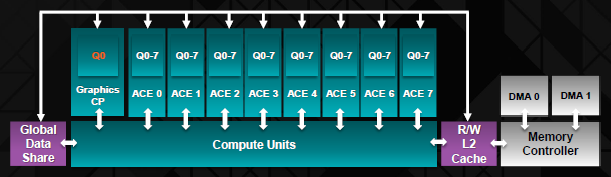
Il throughput di calcolo, inoltre, è stato indirizzato tramite 8 ACE (Asynchronous Compute Engines, Motori di Calcolo Asincroni) al posto dei 2 di Tahiti. Non solo hanno accesso diretto alla Cache L2 e ai Data Stream gestiti da tutte le unità di calcolo, ma possono anche gestire 8 code di calcolo. Prima di passare per gli engine DMA, i dati elaborati dagli ACE passa per il memory controller. In particolare, i motori DMA sono in grado di saturare il bus bidirezionale di uno slot PCI-E 16x di tipo 3.0, tuttavia le prestazioni computazionali di questa particolare architettura non giungeranno mai a richiedere tutta quella banda passante, in quanto la maggioranza dei calcoli viene effettuata direttamente dalla GPU.
Hawaii: gestione dei clock dinamica–>
Con entrambe AMD e nVidia a spremere dal processo produttivo a 28 nm quante più prestazioni possibili, entrambe hanno combattuto per ottimizzare i consumi energetici e la produzione di calore. La tecnologia PowerTune fu lanciata da AMD per contenere questi tre fattori (prestazioni, energia, calore) entro limiti modificabili solo tramite overclock. Con questo metodo, sia i consumi che le prestazioni venivano limitate, ma a differenza del GPU Boost di nVidia, non teneva in considerazione le infinite variabili intorno ad esso, come le temperature e l’overhead di potenza assorbibile. Un esempio esplicativo è, ad esempio, il differente approccio alle frequenze tra una HD7970 GHz Edition ed una GTX 780. La scheda AMD spinge le frequenze a 1050MHz indipendentemente dalla temperatura della GPU, mentre la GTX 780, d’altro canto, ha la possibilità di sfruttare l’ottima dissipazione termica del proprio design reference (e non solo) portando la GPU a clock incredibilmente superiori, rispetto all’irrisorio aumento che ritroviamo nelle schede “rosse”. Con le R9-290/R9-290X, AMD mette da parte questo approccio arcaico e anziano, implementando un nuovo modello di bilanciamento tra prestazioni ed efficienza.
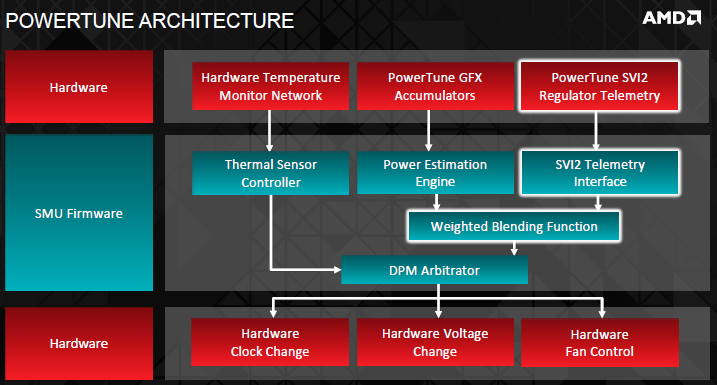
Fondamentalmente, la “filosofia” alla base del PowerTune è rimasta la stessa (ovvero, performance legate strettamente al consumo energetico), ma AMD ha aggiunto una serie di features volte a gestire in modo ottimale il clocking dinamico della scheda, prendendo spunto soprattutto dal segmento APU, in cui AMD sta avendo un discreto successo. Così come la precedente iterazione del PowerTune, i sensori di temperatura e attività sono sparsi sulla GPU per determinare quanta corrente effettivamente viene utilizzata da essa. In precedenza, molti di questi valori venivano stimati, piuttosto che calcolati alla fonte. AMD, con questa iterazione, ha aggiunto un gruppo ulteriore di sensori, che monitora attivamente l’ammontare effettivo di energia assorbita, il tutto tramite i VRM della scheda. Questi dati vengono poi combinati con i valori stimati, in modo da “triangolare” i valori effettivi e il “fabbisogno energetico” della scheda. Grazie alla telemetria energetica e termica che confluisce nell’arbitratore di gestione dinamica di potenza (DPM Arbitrator), il nuovo PowerTune può finalmente effettuare scelte basandosi su dati raccolti in tempo reale, piuttosto che su supposizioni. In questo modo, ad AMD è permesso di impostare le migliori frequenze possibili da quella combinazione di energia consumata, temperature e velocità della ventola. Ciò significa che è possibile a stati diversi di questi tre fattori frequenze simili. Uno dei fattori cruciali nel nuovo PowerTune è il fatto che ora all’utente viene data piena libertà sulla personalizzazione delle curve di gestione del sistema. In soldoni, se volete una scheda silenziosa ma fresca potete abbassare la velocità e i clock per ottenere consumi minori e quindi temperature inferiori, o potete ignorare la rumorosità ed avere il massimo consumo energetico e clocking che la scheda permette. Finalmente, all’utente viene dato il controllo totale della gestione di questi parametri.
La seconda generazione di regolatori di tensione, utilizzata su questa famiglia di GPU, permette di bilanciare dinamicamente tutti gli aspetti dello spettro energetico della scheda. Il controller si assicura di mantenere il consumo energetico entro un limite dello 0.5% di varianza rispetto ad un target di potenza, refreshando voltaggi e frequenze fino a 500 volte al secondo. In questo modo, aumenta la granularità delle frequenze, senza picchi e valli nella gestione dei clocks. La parte migliore di tutto ciò è che sarà totalmente personalizzabile, tale gestione, consentendo il controllo dei parametri operativi tramite il software AMD.

Ovviamente, tutto ciò che abbiamo detto finora fa assumere alla ventola un valore tutt’altro che marginale nell’equazione del nuovo PowerTune. Precedentemente, il controller integrato regolava la velocità della ventola in modo “scripted”, mentre adesso il fan controller è completamente dinamico, gestendo in tempo reale e in maniera predittiva la velocità delle ventole, senza sbalzi di velocità, ma con curve meno aggressive.
Hawaii: Eyefinity reinterpretato–>
Mentre Eyefinity può non essere una prerogativa della maggioranza dei gamers, i pochi che utilizzano 3 o 6 schermi formano un gruppo esigente di utenti enthusiast. Sfortunatamente, in passato, utilizzare una singola scheda per una configurazione Eyefinity rappresentava un limite per via delle connessioni miniDP presenti nel pannello di uscite, visto che era necessario utilizzare uno di essi per gestire tre monitor o più. Ciò significava comprare un monitor con tale ingresso o comprare adattatori di tipo to Display Port, che presentano comunque un costo non proprio contenuto.

Sulle nuove R7/R9, all’utente verrà lasciata la possibilità di pilotare 3 schermi senza passare dalla porta DisplayPort, anche se c’è da dire che a parte la R9-290X e la R9-290, nessuna scheda ha abbastanza potenza per gestire 3 monitor da 1920×1080 Pixel, a meno che non utilizziate più schermi per motivi di lavoro e non per giocare ad altissima risoluzione. Tali funzionalità permangono anche nelle schede di fascia bassa della
serie R7, in modo da permettere a chiunque voglia una soluzione multi-schermo, senza per forza di cose spendere tanti soldi in una scheda da gaming, aumentando la produttività lavorativa senza appunto sborsare molto. 
Molte schede appartenenti alla serie R sono equipaggiate con 2 connettori DVI-D, una porta HDMI 1.4a ed una DisplayPort 1.2. Mentre è possibile utilizzare infinite combinazioni di schermi, alcune R9-280X saranno equipaggiate con un layout leggermente diverso, ovvero due mini DP al posto della singola DisplayPort. In quel caso, il supporto esteso ad Eyefinity tramite HDMI e DVI semplifica di gran lunga le cose. Fate attenzione: abbiamo parlato di connettori DVI-D sulle 290/290X, ovvero non sono presenti i pin necessari agli adattatori DVI-to-VGA, lasciando tale prerogativa alle schede di fascia inferiore.

Per l’Eyefinity a 6 schermi, il connettore DisplayPort 1.2 delle nuove schede consente di pilotare un hub MST (Multi Stream Transport) in modo da “spezzare” un singolo segnale DisplayPort in tre segnali differenti di qualsiasi tipo, creando una “daisy chain” con gli altri 3 connettori della scheda.
Hawaii: TrueAudio, innovazione a 360°–>
Pensando ai videogiochi in relazione alle schede video, la prima cosa che balza alla mente è la velocità di elaborazione dell’enorme quantità di dettagli a schermo, insieme alla qualità di tutto ciò. Tuttavia, il fotorealismo determina solo in parte l’immersione del giocatore nel proprio titolo preferito, ed un’altra buona parte di tale immersione è data dal sistema audio alla base dei giochi, aspetto spesso sottovalutato e talvolta cruciale nel coinvolgimento totale del player nelle scene renderizzate. La qualità effettiva dell’audio multicanale posizionale occupa un ruolo fondamentale nell’immersione del giocatore, ma spesso le soluzioni disponibili al momento non soddisfano gli standard imposti dalla qualità grafica. Insomma, per quanti milioni di dollari uno sviluppatore spenda in un titolo videoludico, non troveremo mai colonne sonore ai livelli di Hollywood, come, per fare un esempio concreto, le musiche di Hans Zimmer in Inception.

Nonostante l’assenza di tracce audio ad alta qualità da parte degli sviluppatori, i tentativi non mancano. Infatti, i middleware e i software capaci di semplificare il lavoro del rendering audio sono già presenti sulla piazza, ma gli sviluppatori hanno un ammontare limitato di risorse CPU con cui lavorare. Fondamentalmente, la maggior parte della CPU viene impegnata per la gestione del programma, dell’AI, della fisica, dei calcoli, del corretto indirizzamento dei dati alla scheda video e a tutta una serie di meccanismi invisibili al giocatore. Come è lecito aspettarsi, l’audio occupa approssimativamente solo il 10% delle risorse presenti nel sistema, non ricevendo le attenzioni che merita. Ed è qui che TrueAudio entra in scena. Mentre la scheda audio e altre forme di renderers audio esterni possono scaricare una parte del lavoro da parte del processore, in fin dei conti non si occupano della vera e propria produzione dell’audio, e TrueAudio, rimanendo in background, agisce come “facilitatore” del carico del rendering audio e della creazione del suono, permettendo, parlando dalla prospettiva dello sviluppo, di liberare risorse CPU per altri compiti. TrueAudio è una pipeline audio ad alta programmabilità e permette di decodificare, codificare, mixare e gestire tutti gli aspetti sonori con un’elevata versatilità, permettendo agli sviluppatori di indirizzare altrove le risorse impegnate per la creazione dell’audio di un gioco. Per contestualizzare il ruolo di TrueAudio, potremmo paragonarlo allo sviluppo di un motore grafico. Gli ingegneri del suono e i programmatori, di solito, registrano suoni dal mondo reale mixandoli poi insieme, combinando vary layers, per creare un dato effetto. Il giocatore ha bisogno di udire uno sparo? Registralo e mixalo di conseguenza. C’è molta poca flessibilità, non si ha a che fare con poligoni e triangoli e texture. TrueAudio permette ai team assegnati allo sviluppo audio di semplificare tali operazioni, fornendo algoritmi personalizzati senza preoccuparsi dell’overhead della CPU, in modo da produrre audio ad alta fedeltà senza incorrere in un hardcap di risorse del processore.
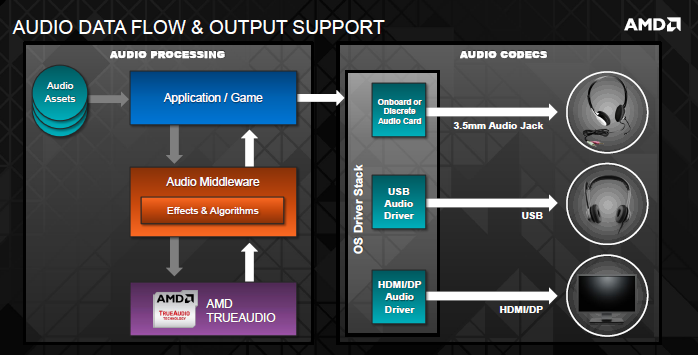
Secondo AMD, una delle migliori caratteristiche del TrueAudio è la trasparenza fornita agli sviluppatori, visto che l’accesso alle risorse da esso predisposte è identico a quello che si effettua tramite le attuali risorse audio. Nessun nuovo linguaggio, nessun programma di terze parti per reindirizzare le risorse, tutto avviene automaticamente, lasciando piena libertà ai tecnici audio. La posizione di TrueAudio all’interno dello stack audio migliora la sua percezione, facendolo inquadrare come un meccanismo facilitante di tutta la gestione sonora, grazie al fatto che tutto ciò che fa avviene in background. Le tracce audio con un supporto alla tecnologia vengono passate al motore TrueAudio on-die, tornando poi alle risorse Windows Audio, in modo da poter essere riprodotto come qualsiasi altra fonte sonora, sia essa attraverso la scheda audio, una porta USB o una connessione HDMI/DisplayPort. Non prende il posto della scheda audio, sia chiaro, ma permette che l’audio codificato abbia una qualità maggiore con un impatto pari allo 0% sulle risorse di calcolo celntrali.
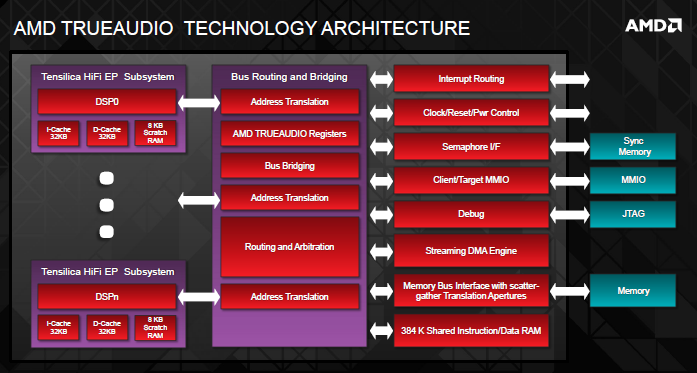
TrueAudio è implementato direttamente nelle schede grafiche che lo supportano (HD7790, R7-260X, R9-290 e R9-290X) tramite un set di core DSP dedicati (Tensilica HiFi EP) localizzati direttamente sul die della GPU. Questi core verranno dedicati al processing dell’audio nei giochi, calcolando fonti sonore sia a virgola fissa che a virgola mobile, dando significanti aumenti di libertà alle software house rispetto ad ora. Tali cores si occupano anche di gestire il processing audio, slegandosi totalmente dai cicli di calcolo del processore centrale. Per assicurare un accesso rapido e senza ritardi, i DSP dispongono di un accesso rapido alla memoria locale, grazie alla cache on-board e alla RAM. Inoltre, un set di istruzioni condivise dal motore DMA aiuta a processare l’audio attraverso i vari stadi. Ancora più importante, l’output dei calcoli effettuati da tali DSP è collegato direttamente alle pipeline dei display, in modo da “non rimanere indietro” rispetto alle risorse grafiche. Mentre TrueAudio assicura che il processing dell’audio venga effettuato sui DSP dedicati piuttosto che sui core grafici, è comunque possibile implementare i calcoli effettuati dalla CPU, alleggerendo comunque il carico, o mantenendolo inalterato, aumentando al contempo l’immersione sonora.
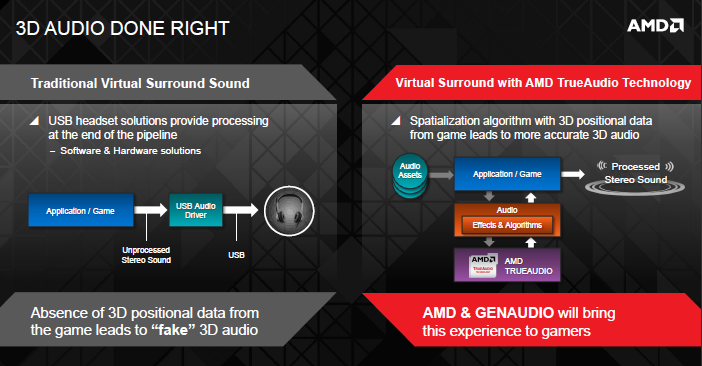
Una delle sfide maggiori per gli ingegneri del suono è la creazione di un audio tridimensionale attraverso cuffie stereofoniche. In un setup tipico, il motore ingame effettua il processing iniziale, mixando poi le tracce in un semplice segnale stereo. I DSP secondari addizionali, di solito posizionati sull’amp USB delle cuffie, si occupano poi di renderizzare la traccia in un surround virtuale su due canali, aggiungendo riverberi, separazioni e altri “trucchi” per creare virtualmente un suono posizionale. Il risultato, spesso, è mediocre, in quanto l’audio tende a perdersi più che a definirsi di più. TrueAudio assiste la virtualizzazione, offrendo script preimpostati per il processing. Viene utilizzato un DSP ad alta qualità che assicura che ogni singolo canale audio venga separato e indirizzato in una propria pipeline dedicata. AMD ha collaborato con GenAudio per consentire ciò, e dalle slide viste finora, sembra che abbiano creato qualcosa di davvero incredibile.
Mentre dal lato dello sviluppo nulla cambia, questa nuova addizione permette non solo un’ottimizzazione delle risorse CPU. Effetti avanzati, uno stadio sonoro più ricco, tracce vocali più chiare e molto altro ancora può essere gestito grazie al minor overhead e al supporto esteso alle applicazioni già esistenti. In aggiunta, i limitatori di mastering permettono ai suoni individuali di essere riprodotti senza distorsioni. A differenza di alcune applicazioni, TrueAudio non è una magica sfera di cristallo che risolve tutti i problemi del mondo, in quanto è progettata per tracciare come obiettivo flussi ad alta definizione, in modo che non tutte le fonti audio vengano elaborate da esso. AMD non taglia fuori la CPU dall’equazione di calcolo, piuttosto fa in modo da creare un ambiente di calcolo eterogeneo e con ruoli specifici per ogni unità di elaborazione.

Come con tutte le iniziative, il fallimento o il successo di TrueAudio dipenderà soprattutto dal desiderio degli sviluppatori di supportarlo o meno. Per quanto possa sembrare un “deja-vu” come con HD3D, Bullet Physics e altri concetti di marketing di AMD degli anni passati da cui non si è mai schiodata, è molto probabile che TrueAudio sia una soluzione che riuscirà a brillare. Gli sviluppatori sono già al lavoro, e AMD ha sofferto molto per rendere il processo di sviluppo quanto più friendly possibile. L’audio è una delle poche frontiere che non è stata ancora esplorata; tutto ciò che migliora l’audio nell’esperienza dei PC è la benvenuta, ma non aspettatevi miracoli. Molto probabilmente le vostre cuffie e le vostre schede audio non avranno cambiamenti sostanziali, ma sistemi più grandi, setup più potenti, potranno avere finalmente la giustizia che meritano. AMD ridefinisce, in pratica, l’audio con le proprie schede video.
Hawaii: Mantle, asso nella manica?–>
Per capire da dove proviene Mantle, dobbiamo tornare indietro nel tempo e prendere la PlayStation 3 come esempio di come AMD vuole cambiare il modo in cui i giochi interagiscono con il sistema grafico del PC. Mentre il processore Cell della PS3 e i core grafici associati sono difficili da programmare, giochi come Uncharted 3 e The Last of Us portano con loro una grafica migliore a molti titoli PC recenti, nonostante l’hardware di oggi sia qualcosa di inimmaginabile, rispetto all’hardware di lancio della console. Come è possibile? Le console danno agli sviluppatori un accesso facilitato al sottosistema grafico, senza driver grafici, overhead prodotto dalle API, un OS che ostruisce e altre eccentricità non necessarie che divorano risorse importanti. Il risultato è che i giochi per console sono capaci di utilizzare al 100% una risorsa data, permettendo ai programmatori di fare di più con meno. In alcuni casi (la PS3 è ancora un esempio che calza a pennello) il passaggio che consente di utilizzare appieno tali risorse come programmatori richiede un approccio totalmente diverso ad una piattaforma hardware, reimparando, di fatto, a programmare. Qui, interviene AMD a rendere il processo meno arduo ed accessibile a tutti.

Mantle è stata creata per ridurre il numero di ostacoli tra gli sviluppatori e ciò che vogliono creare quando creano un nuovo gioco o quando vogliono effettuare un porting dalle consoles. In passato, cose come l’ottimizzazione della CPU e l’efficienza nella comunicazione tra componenti erano categoricamente ignorate, con gli sviluppatori alle prese con un’infinità di configurazioni hardware possibili, con CPU multicore non sfruttate a dovere, risorse GPU sprecate e la mancanza di un’ottimale condizione prestazionale sul PC, malgrado l’hardware più avanzato. C’è inoltre una larga componente software nell’ambiente PC, in quanto i programmatori, per accedere alle risorse, devono passare da software, sistemi operativi e driver che comunque inspessiscono la distanza tra loro e l’hardware. Ciò è un problema di non poco conto, che porta all’interazione software-memoria a quella che potrebbe essere paragonata ad un semaforo con il verde che dura pochi secondi, come un collo di bottiglia che limita il throughput computazionale. Le DirectX 10 e 11 hanno cercato di indirizzare nella maniera corretta molti di questi blocchi, ma le prestazioni generali sono comunque ancora limitate dal fatto che sono API ad alto livello. Insomma, la comunicazione da loro gestita tra API, GPU, gioco e CPU è ancora forzata in canali stretti, qualcosa che gli sviluppatori non vorrebbero trovarsi davanti. Utilizzando API ad alto livello (come, appunto, DX10 e 11), vengono effettuate un elevato numero di chiamate di drawing, che portano inevitabilmente a saturare i cicli di calcolo della CPU: in pratica, le architetture grafiche odierne non possono esprimere tutto il loro potenziale.
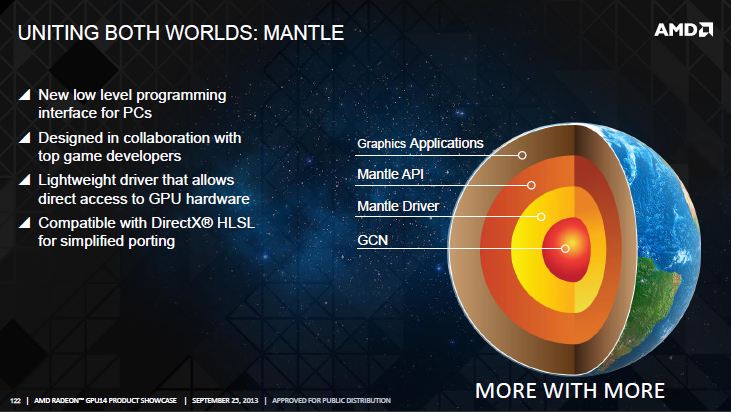
Qui interviene Mantle, con la sua introduzione nell’equazione: non un rimpiazzo diretto delle DX e delle OpenGL, ma una forza complementare ad esse. Essa è un’API che si focalizza sul metallo nudo e crudo, programmazione a basso livello con un driver leggerissimo, che gestisce efficacemente la distribuzione delle risorse, garantisce controlli addizionali sull’interfaccia della memoria grafica e ottimizza le suddette chiamate di drawing. Pensate di Mantle come un mitragliamento a bassa quota che bersaglia componenti chiave, piuttosto che un bombardamento a tappeto che non garantisce pienamente che un obiettivo venga colpito. Con una linea di accesso più diretta alla GPU, AMD spera che le performance di GCN aumentino drasticamente, incrementando l’efficienza piuttosto che mettere alla base del problema una maggiore potenza grezza. Aprire a nuove tecniche di rendering che non sono legate alle API odierne è una possibilità. Teoricamente, ciò permette a Mantle di processare chiamate di drawing superiori del 900%, e ancor più importante, permette di portare giochi da console a PC e viceversa con tutte le ottimizzazioni delle risorse del caso.

Ovviamente, ci sono delle limitazioni per questo approccio. Mentre le API di alto livello rimarranno le stesse (DX, D3D) tra le varie aziende hardware, Mantle sarà compatibile solo con GCN. Questa è un’ottima notizia per tutti coloro che utilizzano una scheda HD7000 o superiore o chi possiederà una nuova console, ma gli utenti in possesso di schede GeForce o Intel HD4000 verranno lasciati fuori, in quanto almeno per il momento né nVidia né Intel hanno soluzioni paragonabili o compatibili. Persino le schede precedenti a GCN sono state messe da parte in favore del progresso. Con ciò a mente, gli sviluppatori potrebbero essere costretti a bypassare il supporto a hardware non recente, aggiungere Mantle come opzione selezionabile o semplicemente ignorare Mantle finché i prodotti compatibili siano fuori commercio. Senza dubbio AMD ha vinto la corsa alle prossime generazioni di console, grazie alle APU Jaguar su entrambe XOne e PS4, cosicché questi design facciano parte integrante della loro strategia futura. Purtroppo, è stato detto davvero molto poco riguardo alle API ad alto e basso livello utilizzate in questi prodotti, in primis l’Xbox One, le Direct3D 11.2 sono date per scontate, ma nessuno sa di cosa si tratti scendendo al basso livello. Microsoft ha anticipato tutti dicendo che Mantle non verrà utilizzata come API a basso livello, ma includendo la compatibilità HLSL DirectX di cui dispone la console potrebbe far avverare i sogni dell’azienda a lungo termine. Sotto molti aspetti, questo approccio ci ricorda le Glide di 3DFX, un’altra API a basso livello sviluppata anni fa ma fallita miseramente per la mancanza del supporto di sviluppatori e per la dismessa dell’azienda che le creò, 3DFX, appunto. Una delle maggiori sfide nel fare qualcosa al di fuori dei tipici ambienti DX/OpenGL è vendere l’idea agli sviluppatori. Mantle può aver mostrato promesse senza fine, ma abbiamo visto già una pletora di tecnologie simili messe da parte per via di uno scarso supporto dall’industria. Stavolta, però, AMD ha sostenitori di grande rilievo già dal day one.

Se AMD avesse utilizzato un piccolo studio di sviluppo per diffondere le proprie API, molti poche aziende l’avrebbe presa sul serio. Invece, hanno raggiunto subito credibilità grazie al supporto di EA e, di conseguenza, di DICE. Una combinazione responsabile della creazione della serie multimiliardaria di BattleField, considerata un caposaldo dell’industria dei videogiochi. Secondo Johan Andersson, Lead Designer di DICE ed evangelista rispettato della tecnologia avanzata del PC, Mantle è uno sforzo collaborativo tra AMD, EA, DICE e altri studios. Il risultato è che il Frostbite 3 di DICE supporterà nativamente le nuove API a basso livello. È un affare non di poco conto, se considerate il largo numero di titoli tripla A che useranno tale motore. Need For Speed: Rivals, Dragon Age: Inquisition, Star Wars Battlefront, BattleField 4, sono tutti titoli che utilizzeranno il Frostbite 3 e che potrebbero potenzialmente includere un’opzione per Mantle. Gli altri sviluppatori seguiranno a ruota visto che Mantle è stata creata per soddisfare le esigenze di essi, quando ci si trova di fronte alla creazione di un titolo PC o di un porting.

Il primo titolo ad includere il supporto a Mantle sarà l’incredibilmente anticipato Battlefield 4. Comunque, Mantle verrà diffuso solo in una patch di Dicembre, due mesi dopo il rilascio iniziale, avvenuto proprio pochissimi giorni fa. Ciò pone ottime basi in quanto dimostra che Mantle può essere implementato in un gioco con una patch, senza stravolgere il codice sottostante e offrendo al pari del Source Engine un’opzione di switching tra le modalità di rendering. Ovviamente, siamo fortemente interessati ai boost prestazionali che può fornire rispetto ai competitors. Considerando tutto ciò, dove si colloca Mantle nel panorama attuale delle API? Non ne siamo ancora sicuri, visto che la tecnologia è ancora ai primi stadi. A giudicare dalla reazione dei siti internet in giro per il mondo sul suo annuncio, gli sviluppatori già aspettano con clamore di avere accesso alle versioni per PC. Un segno incoraggiante, insomma. Comunque sia, come Mantle si evolverà attraverso la sua iterazione attuale dipende dal desiderio di AMD di supportarla negli anni a venire, ed è qui che si pone un grande punto interrogativo. Vista l’associazione vicina alle console e all’abilità di facilitare i porting su e da PC, dal punto di vista di sviluppo ed ingegneria hardware, dovrebbe essere una scelta ad occhi chiusi, quindi ci sono ottime speranze che il supporto non verrà tagliato molto presto, anzi, si prospettano ottime applicazioni per quest’API.

Mantle e il suo lancio ci dicono un bel po’ di cose: il rapporto di AMD con gli sviluppatori inizia a ripagare concretamente, l’inclusione dell’architettura GCN sulle console di next-gen si sta mostrando un fattore molto più cruciale di quanto nVidia ha cercato di far pensare, e AMD stavolta è seria da morire sulla focalizzazione sul gaming. Mantle è un filone comune che connette così tante iniziative che può essere davvero l’occasione di AMD di far brillare tutto ciò che è presente nel suo portfolio, dalle prossime APU Kaveri alle GPU discrete alle console.
Galleria fotografica: AMD FirePro W9100–>
Di seguito, una galleria di foto della scheda video e del bundle:





Configurazione di prova e metodologia di test–>
La configurazione utilizzata per i test è la seguente:
| CPU | Intel Core i7 5960x |
|---|---|
| Heatsink | AlphaCool NexXxos Cool Answer 360 D5/XT |
| Mainboard | ASUS ROG Rampage V Extreme |
| RAM | Corsair Dominator Platinum DDR4 16 GB 2666 MHz |
| VGA | AMD FirePro W9100 16 GB GDDR5 |
| Sound Card | Creative SoundBlaster Omni 5.1 e Creative T30 Wireless Speakers |
| HDD/SSD | Corsair Neutron XT SSD 480 GB |
| PSU | Corsair AX1500i Digital PSU |
| Case | Corsair Graphite 780T Arctic White |
| Monitor | Acer CB280HK 4K Display |
| Keyboard | Corsair Gaming STRAFE |
| Mouse | Corsair Gaming Sabre RGB Laser |
| OS | Windows 10 Pro x64 |
I benchmark utilizzati per testare le prestazioni in Floating Point a singola precisione e doppia precisione sono i seguenti:
- Cinebench R15
- Folding@Home Benchmark
- SPECviewperf 12
- CompubenchCL
Benchmark: Cinebench R15–>
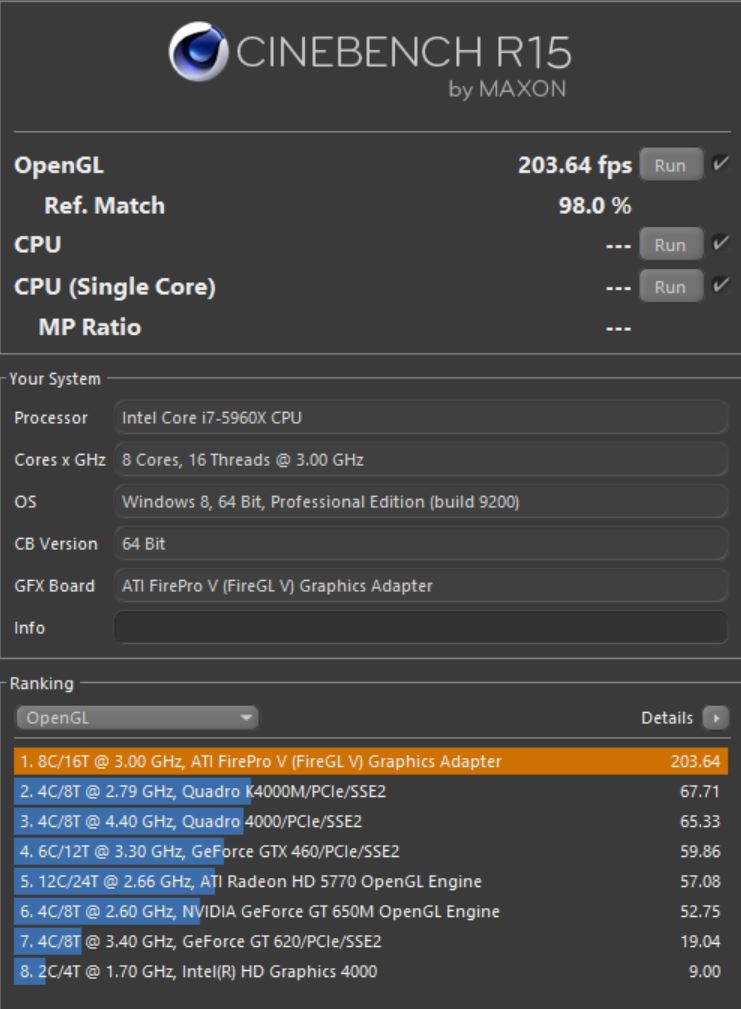
Maxon, azienda dedicata ai software di renderizzazione 3D, è nota agli addetti nel settore per programmi come Cinema4D e VRay, programmi di modellazione e rendering 3D; dal 2010, la software house mette a disposizione, in maniera gratuita, un benchmark per l’efficienza di calcolo del sistema CPU-Mainboard-RAM, ovvero Cinebench, disponibile in due varianti, R11.5 e R15.
Un secondo benchmark, invece, testa le prestazioni delle GPU in rendering, simulando la scena di un inseguimento tra due auto che finisce davvero molto male per una delle due:
Benchmark: Folding@Home–>
Folding@Home è un network di calcolo distribuito che, tramite una serie di progetti, elabora ed analizza la somministrazione di energia a specifiche proteine, in modo da simulare il ripiegamento delle proteine.
Perché tutto questo “trambusto”? Semplice: tali meccanismi, utilizzando milioni di PC al mondo, permettono di trovare le cure a malattie di cui si ignora ancora la causa o che magari non hanno ancora una cura. Il benchmark a disposizione di F@H consente di sapere quante unità si riescono ad elaborare nell’unità di tempo:
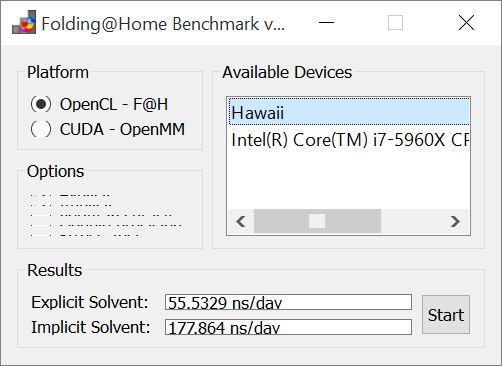
Benchmark: SPECviewperf 12–>
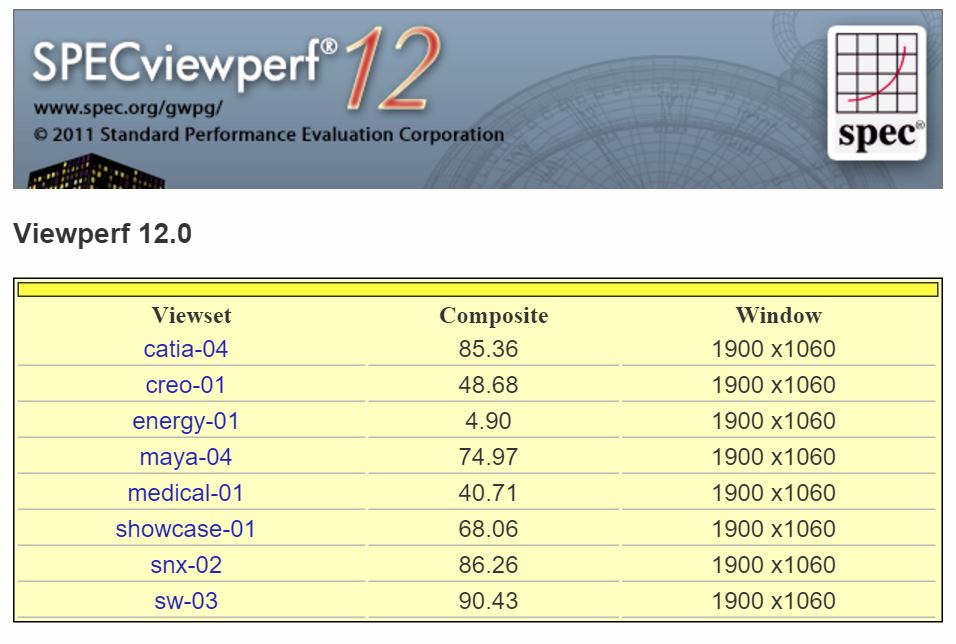
La Standard Performance Evaluation Corporation (SPEC) è un’azienda no-profit il cui scopo è, fin dal 1988, di creare una suite di benchmark standardizzata per PC. Lo SPECviewperf è il benchmark della software house adibito al testing delle performance grafiche in rendering CAD/CAE in 2D e 3D. La suite di test di questo benchmark include i set CATIA, Creo, Energy, Maya, Medical, Showcase, Siemens NX e Solidworks, testando quindi molti dei programmi di rendering utilizzati dall’industria dell’automotive e dell’aeronautica:
Benchmark: CompubenchCL–>
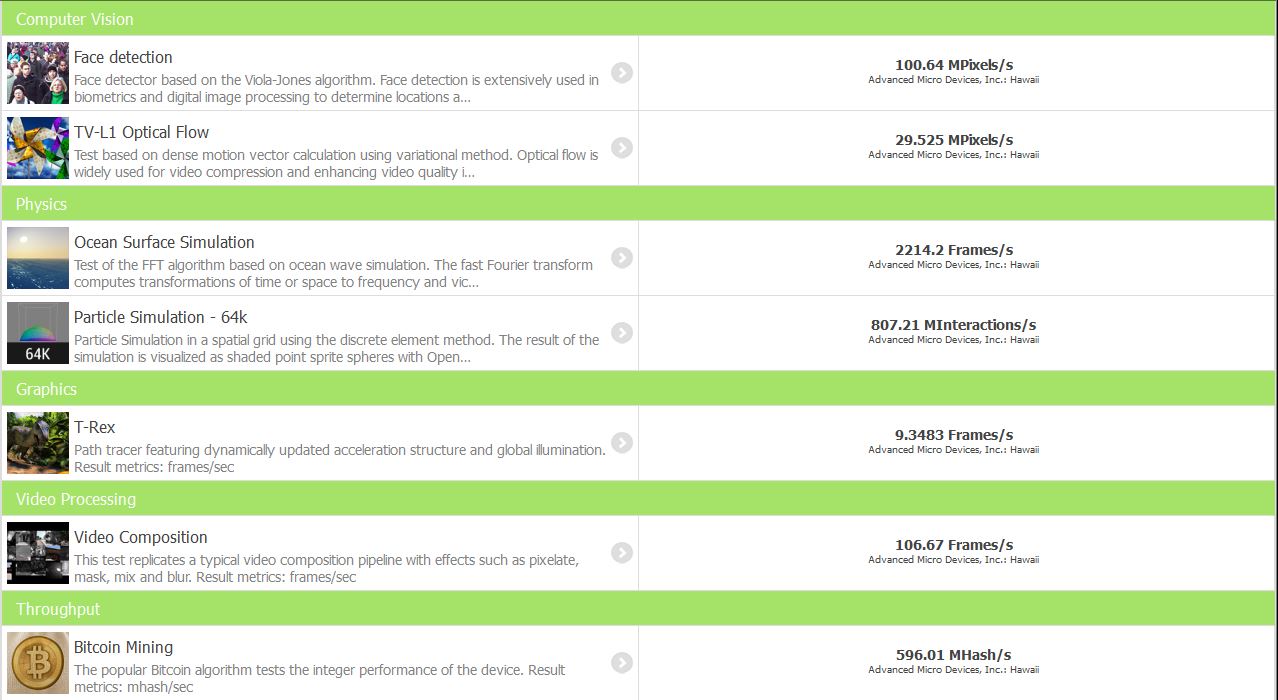
Kishonti Informatics, una delle aziende quotate nella NASDAQ-100, è specializzata nella creazione di soluzioni di calcolo e grafica ad alte prestazioni. Per poter attestare le prestazioni dei propri sistemi, l’azienda ha creato un benchmark denominato CompuBench, disponibile in varie versioni ed edizioni a seconda dell’aspetto da analizzare. Per testare le prestazioni in rendering, utilizziamo CompuBench OpenCL:
Considerazioni finali–>
[conclusione]
[titolo]Design e qualità costruttiva[/titolo]
A differenza della 290X (versione consumer della stessa GPU), la FirePro W9100 presenta dimensioni superiori ed una backplate che, oltre a irrigidire la struttura della scheda, consentono di tenere più fresca la GPU, che durante intense sessioni di computing non ha superato gli 80°C in full.
[voto=”9″]
[/conclusione]
[conclusione]
[titolo]Prestazioni[/titolo]
Non abbiamo un termine di paragone in quanto è la prima scheda grafica professionale che testiamo (NVIDIA, se ci sei, batti un colpo e mandaci la controparte “verde”), ma basandoci sui risultati di altre recensioni, la scheda si scambia colpi con la NVIDIA Quadro K6000, prevalendo in alcuni test e finendo seconda di poco in altri. La peculiarità della scheda è, però, la capacità di gestire fino a 7 monitor, 6 dei quali in 4K “autentici” (ovvero 4096×2160, risoluzione superiore allo standard Ultra HD che viene utilizzato in ambito desktop).
[voto=”9″]
[/conclusione]
[conclusione]
[titolo]Compatibilità e consumi[/titolo]
Compatibilità: la scheda sempre non aver ben digerito una piattaforma Z87, mentre non ha dato alcuni problemi su piattaforma X99 e Z170. Ovviamente la scheda è indirizzata ad un settore professionale e pertanto si suggerisce di utilizzarla in server o almeno in “home server” che utilizzano componenti di tipo WS (come ad esempio la ASRock X99 WS-E da noi recensita alcune settimane fa) in modo da garantire la massima intercompatibilità. La scheda ha un assorbimento massimo dichiarato di 275W ma durante i nostri test non ha superato i 230W di picco.
[voto=”8″]
[/conclusione]
[conclusione]
[titolo]Prezzo[/titolo]
La scheda ha un prezzo di 3625€ presso ePrice, unico rivenditore autorizzato per le schede FirePro di AMD (targate Sapphire). Il prezzo è elevato, certo, ma in termini di workstation e performance in rendering la scheda ha in realtà un rapporto prezzo/prestazioni davvero formidabile, soprattutto in rapporto alle soluzioni concorrenti. Vi invitiamo ad acquistare presso i rivenditori ufficiali Sapphire, in quanto pur presentando un prezzo superiore ai VAT Player (coloro che evadono l’iva tramite meccanismi al limite della legalità), forniscono supporto post-vendita/RMA, cosa che suddetti rivenditori non ufficiali non gar0antiscono.
[voto=”8″]
[/conclusione]
Per concludere, non possiamo che dare alla AMD FirePro W9100 il nostro Hardware Gold Award, sia per le elevate performance che per il rapporto prezzo/prestazioni superiore alla concorrenza:

Ringraziamo Sapphire Italia e AMD per il sample oggi recensito.
Seguiteci sui nostri social network:
La recensione
AMD FirePro W9100
Una scheda potente, con tante features ed un prezzo che può interessare agli enthusiast e ai prosumer nel mondo del rendering e del calcolo avanzato in OpenCL.
Pro
- Rapporto prezzo/prestazioni elevato
- Supporto a 6 display 4K: tanto spazio per lavorare in alta risoluzione
- 16GB di memoria RAM
Contro
- Consumi elevati rispetto alla concorrenza
AMD FirePro W9100 Prezzi
Raccogliamo informazioni da vari negozi per indicare il prezzo migliore

![[COMPUTEX 2026] be quiet! svela tanti nuovi prodotti al Computex](https://www.rehwolution.it/wordpress/wp-content/uploads/2026/06/bq-computex2026-pure-base-803-4x5-5-350x250.jpg)
![[COMPUTEX 2026] Noctua e Carbice insieme per il raffreddamento DIY](https://www.rehwolution.it/wordpress/wp-content/uploads/2026/06/noctua_nt_cp1_am5_4_announcement_post_v4-scaled-350x250.jpg)



Discussione su post