
ASRock X399 Taichi: introduzione e specifiche tecniche–>
![]()
Ci siamo! Come anticipato alcune settimane fa durante la recensione della ASRock Fatal1ty X399 Professional Gaming, vi abbiamo detto di come ASRock disponesse di un’ulteriore scheda madre, dal costo inferiore ma praticamente dallo stesso livello di features e performance: la X399 Taichi.

Ebbene, oggi abbiamo sul nostro scintillante banchetto da battaglia proprio questa eccezionale scheda madre, dal design stealth (come da recente “tradizione” AMD) e dall’equilibrio perfetto tra prezzo, performance e features, in piena filosofia Taichi.
Senza tanti giri di parole, parliamo subito delle specifiche tecniche di questa mainboard. Per ulteriori informazioni e per scaricare i driver più aggiornati, vi invitiamo ad andare sul sito ufficiale di ASRock:

Ovviamente, prima le cose “ovvie”: la X399 Taichi è dotata di socket TR4 (SP3r2), e presenta il supporto a tutte le CPU Ryzen Threadripper finora lanciate sul mercato (1900X, 1920X e 1950X); la scheda è dotata quindi di chipset X399, e presenta 8 slot di memoria DDR4 con supporto fino a 128 GB ed una frequenza massima di 3600 MHz (+) in overclock.
Il generoso sistema di alimentazione è affidato a 8+3 fasi (CPU+SOC), tutti International Rectifier IR3555, capaci ognuno di erogare 60 A, per un totale di 480 A per la CPU e 180 A per il SOC (System-On-Chip, ovvero tutto ciò che riguarda i controller on-board della CPU, come quello PCIe, per la connettività e per le RAM), più che sufficienti per alimentare il più spinto degli overclock, sia ad aria che a liquido. Ovviamente, anche le RAM hanno un’adeguata sezione di alimentazione, con 2 fasi per coppia di canali, per un totale di 2+2 fasi, sempre IR3555.
Passando alla connettività, la X399 Taichi presenta entrate, uscite e connettori di tutto rispetto, e qui iniziamo a notare le prime differenze con la Professional Gaming, di cui condivide gran parte del layout: troviamo infatti “solo” 2 porte Gigabit Ethernet (la 10 Gigabit su chip Aquantia AQC107 non è presente), 8 porte USB 3.1 Gen1, 1 porta USB 3.1 Gen2 Type-A ed 1 porta USB 3.1 Gen2 Type-C.
In una configurazione alquanto particolare, il pannello I/O del chip audio, un Realtek ALC1220, stavolta senza il supporto al software SoundBlaster Cinema 3, che garantisce una maggior qualità di playback e più possibilità di personalizzazione della resa audio rispetto ai driver Realtek tradizionali, dovendoci quindi accontentare del sistema Purity Sound 4 originale di ASRock.
Enorme anche la connettività sul fronte dello storage, con ben 8 porte SATA3 e 3 slot Ultra M.2 (32 Gbps), tutti collegati direttamente alla CPU, per una migliore gestione delle linee PCIe e per far sì che al chipset X399 non venga “tolta” nessuna linea PCIe anche in caso si utilizzino 3 SSD M.2.
Troviamo infine due header per porte USB 3.0 frontali e un connettore U.2, che va ad attingere alle linee PCIe dello slot M.2_1 qualora fosse popolato.
Spesso, tra la versione Taichi e la relativa controparte Fatal1ty, una delle features che vediamo scomparire nelle prime sono il Debug monitor e i tasti di avvio e reset on-board: ebbene, sulla X399 Taichi sono entrambi presenti, rompendo una “tradizione” a tutto vantaggio dell’utente. Pensandoci, è più che naturale, visto che comunque, di solito, la Taichi è un modello più economico, mentre qui si parla comunque di una scheda madre da più di 300 €.
Dentro Threadripper: tutto duplicato–>
Nonostante molti dei design precedenti dei processori di AMD non abbiano soddisfatto le aspettative in passato, Zen rappresenta un balzo fondamentale su tantissimi livelli. Come abbiamo già descritto nella review di Ryzen 7, quest’architettura è stato un design nato dal nulla, piuttosto che semplicemente un’evoluzione di prodotti già esistenti. È un’importante distinzione da sottolineare con una lineup di CPU come Threadripper visto che una semplice evoluzione non avrebbe permesso ad AMD nemmeno di pensare di competere nell’ambiente HEDT. Inoltre, i risultati parlano chiaro in fasce di prezzo inferiori; partiamo quindi dall’inizio e scendiamo pian piano nei dettagli.
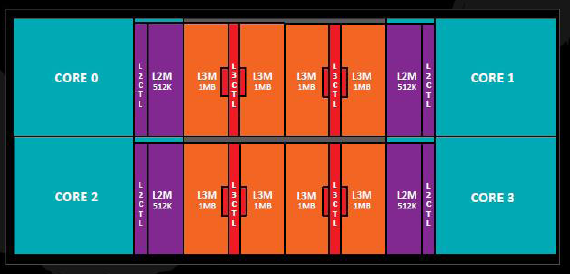
Il mattoncino primario di qualsiasi processore basato su Ryzen è il Compute Complex, o CCX. Ognuno di essi ha 4 cores Zen con 2 MB di cache L2 (512 KB per core), 8 MB di cache L3 condivisa e l’abilità di processare 8 thread concorrenti. Così come gli altri processori basati su Zen, anche Threadripper è dotato di una sfilza di tecnologie SenseMI come Precision Boost, Pure Power, XFR, Neural Net Prediction e Smart Prefetch. Per saperne di più consultate l’articolo su Ryzen 7 linkato qualche riga più sopra.
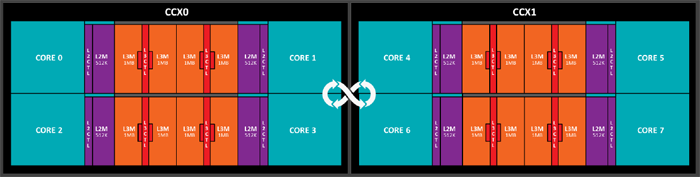
Mettete due di questi CCX insieme che comunicano tra di loro attraverso l’interconnect ad alta velocità di AMD, l’Infinity Fabric, e avrete il layout base di tutte le CPU Ryzen 3, 5 e 7 finora lanciati. Quello che è stato fatto qui è in realtà parecchio interessante, che sia da un punto di vista negativo o positivo visto che ogni die prodotto ha in realtà 8 core. Per creare nuovi SKU, AMD ha semplicemente messo tutti questi die in un processo di binning (=selezione) dove vengono effettuati tagli (letterali, via laser) per le varianti a 4, 6 o 8 Core di Ryzen.
Ovviamente, il mero numero di transistor crea qualche ostacolo sul TDP e sull’efficienza di calcolo, ma l’Infinity Fabric dovrebbe essere abbastanza versatile da (bene o male) compensare. Questo approccio ha anche permesso ad AMD di lanciare in rapida sequenza un enorme numero di processori, facendo pressione sull’intera lineup di Intel senza per fortuna ridisegnare drasticamente i die ogni volta. Come tutto ciò si traduca in Ryzen Threadripper dovrebbe essere abbastanza ovvio ma secondo AMD solo il miglior 5% dei die diventa poi uno di questi processori di fascia alta.
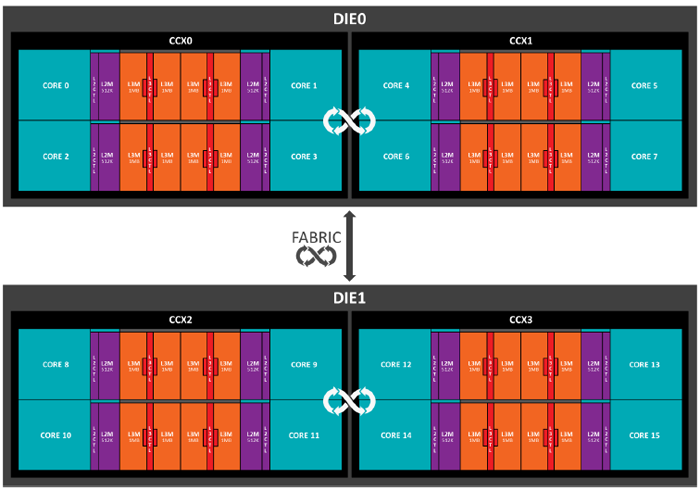
Threadripper prende l’approccio a doppio CCX e lo eleva all’ennesima potenza, semplicemente prendendo una coppia di doppi CCX e installandoli sullo stesso package. Pensatelo come due Ryzen 7 1800X fusi insieme.
Questi due die comunicano tra di loro, ancora una volta, tramite l’Infinity Fabric, risultando in un trio di interconnessioni e di una bandwidth bi-direzionale die-to-die di ben 102.22 GB/s. Detto questo, la struttura ben distinta dei die potrebbe portare con tutta probabilità a latenze on-chip maggiori e minori prestazioni rispetto a un design tradizionale, ma d’altro canto ciò ha permesso ad AMD di stravolgere la sua lineup con un’architettura estremamente scalabile che può essere facilmente adattata in vari scenari d’utilizzo.
Un buon esempio di questa adattabilità è come la lineup di CPU Threadripper sia stata creata. laddove il 1950X ha un insieme di core completamente funzionanti tra i 4 CCX in due die secondo uno schema 4+4|4+4, il 1920X ha un quartetto di core disabilitati uniformemente creando un layout 3+3|3+3. Quasi sicuramente, il 1900X avrà una distribuzione del tipo 2+2|2+2.

Oltre alla potenza grezza di Threadripper, ognuno di questo gigantesci processori funge anche come completo SoC (System-On-Chip). Ognuno ha accesso a 60 linee PCIe 3.0 che possono essere divise tra slot PCIe 16x e storage NVMe e fino a 8 connessioni USB 3.1 GEn1 attraverso la loro interfaccia I/O ad alta velocità. C’è anche posto per un codec audio ad alta definizione integrato. Tale approccio dovrebbe alleviare i colli di bottiglia per i dispositivi di storage ad alta velocità che, su alcune delle piattaforme Intel, deve spartirsi la già ristretta bandwidth su un’interfaccia DMI limitata.
Forse l’aspetto più interessante di questo design è come gestisca le richieste di memoria, e ve ne parliamo nella prossima pagina.
NUMA e UMA: come Threadripper accede alle RAM–>
Una delle sfide inerenti al lavorare con CPU composte da più die è la latenza d’accesso alla memoria. Assistiamo a tale problema sui sistemi multiprocessore e, in margini inferiori, su alcuni dei setup di Intel dalle CPU particolarmente “popolate”. Per metterla in parole semplici, tutto a partire dalle dimensioni fisiche dei core alla lunghezza dell’interconnessione va contro le velocità ottimali di spostamenti nella memoria.

Nel caso di Threadripper, questi effetti sono sia moltiplicati che minimizzati in svariati modi. In ogni processore ci sono due set distinti di memory channel, dove ognuno di questi abbina una coppia di canali con uno dei due die sul package. Mentre questo crea un collegamento veloce di soli 78 ns tra ogni die e il canale “più vicino”, distribuire l’accesso su tutti i canali di memoria può aumentare la latenza fino all’esorbitante numero di 133 ns quando un die dual CCX è costretto a comunicare con i canali più “lontani”.
La ragione di tutto ciò è semplice: i processori Ryzen Threadripper non sono nativamente quad-channels. Piuttosto, AMD ha -per mancanza di una definizione migliore- unito due processori insieme sfruttando l’Infinity Fabric per canalizzare tutte le comunicazioni tra essi. Ciò può causare un notevole aumento della latenza, pertanto un’idea alquanto innovativa è stata implementata: dare all’utente la possibilità di scegliere le modalità di accesso alla memoria.
Distributed Mode
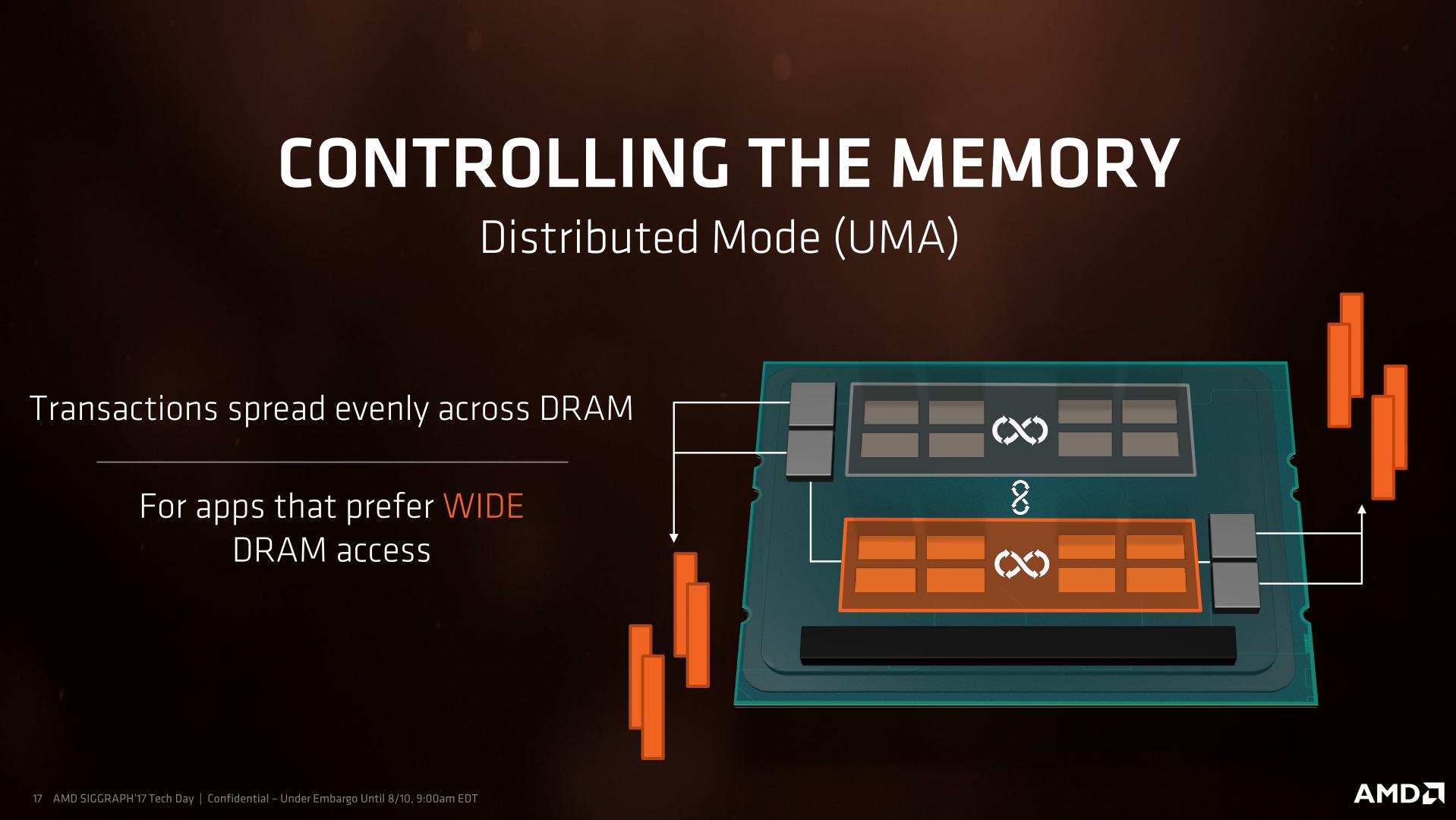
Attraverso il Distributed Mode, il sistema è messo in una configurazione ad Uniform Memory Access, o UMA. UMA significa che gli spostamenti in memoria vengono bilanciati su tutti i canali DRAM, utilizzando l’intero layout dell’architettura quad channel. In essenza, ciò aumenta significativamente la bandwidth disponibile e può beneficiare applicazioni che richiedono un ampio accesso alla memoria come After Effects, Premiere Pro, Blender e 3DS Max.
L’altra faccia della medaglia è che questa configurazione sacrifica la latenza in favore della massima banda passante visto che ognuno dei die cerca di accedere anche ai canali di memoria più distanti. Ecco che quindi entra in gioco il Local Mode nell’equazione di AMD.
Local Mode

Il Local Mode è molto più “subdolo” del Distributed visto che localizza l’accesso alla memoria ai canali che sono fisicamente più vicini ai core che processano il carico di lavoro, posizionando il sistema in una configurazione Non-Uniform Memory Access (NUMA). In molte situazioni in cui Threadripper ha un vantaggio (leggasi: workloads a più thread particolarmente impegnativi) ciò in realtà riduce le performance, visto che abbassa la latenza ma al contempo riduce la banda passante disponibile. Ma c’è un’area chiave dove la configurazione NUMA porta tantissimi benefici: i giochi.
Secondo AMD, la loro ricerca indica che molti titoli beneficiano più di una latenza ridotta che di maggiore bandwidth. Ma non finisce qui, AMD, durante i test interni, ha scoperto qualcos’altro:
Inoltre, il Local Mode (NUMA) suggerisce allo scheduler del sistema operativo che un’applicazione che non utilizza molti thread dovrebbe rimanere in esecuzione su un solo die e preferire la memoria connessa più vicina finché riempita (a tal punto c’è un travaso nella successiva porzione di memoria). Tale residenza in un die minimizza la possibilità che i thread di un gioco (come la fisica, l’IA o il suono) con elevati requisiti di sincronizzazione vengano divisi tra i vari die, generando latenze maggiori. Questo, in aggiunta a latenze inferiori, aumenta specificamente le prestazioni nei giochi.
Sembra quindi che lo scheduler di Windows 10 tratti il setup NUMA come un’entità indissolubile invece che una sezione divisa di due nodi di calcolo distinti. Come risultato il processore potrebbe (in teoria) gestire meglio i carichi di lavoro in-game. Se poi ciò si traduce o meno in realtà, lo scopriremo nelle pagine dei benchmark.
X399: un tuffo nella nuova piattaforma–>
Threadripper è diventato la notizia del giorno per due motivi principali: il numero impressionante di threads e l’incredibile numero di linee PCIe che AMD ha pubblicizzato. Entrambe queste caratteristiche permettono all’azienda di stuzzicare Intel proprio dove fa male visto che i processori nella stessa fascia di prezzo hanno meno threads e un numero di linee PCIe decisamente inferiore.
Sebbene la sua superiorità su carta, AMD ha dovuto cercare un modo per ottimizzare al meglio l’allocazione delle linee PCIe assicurandosi allo stesso tempo che non ci fossero colli di bottiglia quando più dispositivi ad alta bandwidth fossero alla ricerca degli stessi dati nello stesso momento. Ci sono riusciti? Direi proprio di sì, ma anche con 60 (beh, sì, 4 delle 64 linee sono dedicate al collegamento CPU-X399), potrebbe esserci ancora bisogno di qualche compromesso. Onestamente, però, se si arrivano a saturare 60 linee PCIe e il Chipset di Threadripper, forse è meglio guardare altrove, magari su soluzioni server.

Partiamo dall’inizio di tutto con i processori Ryzen Threadripper. Generalizzerò un poco in questa sezione visto che dal 1950X da 999$ al 1900X da 549$ abbiamo la stessa allocazione. In aggiunta, il modo in cui le linee PCIe sono divise potrebbe variare a seconda del produttore della scheda madre, quindi prendete ciò che diremo di seguito come un semplice esempio piuttosto che una regola.
Ogni CPU Threadripper ha accesso a 64 linee PCIe 3.0, quattro delle quali riservate all’interfaccia CPU-chipset. Ciò lascia ancora altre 60 linee PCIe con cui giocare, che possono essere configurate come due slot x16 e due slot 8x per setup fino a quattro schede video. Tuttavia, con entrambe AMD e NVIDIA allontanatesi da un supporto consistente per sistemi a più di due schede, poche se non nessuna scheda madre X399 trarrà veramente vantaggio da un design nativo 16x/16x/8x/8x. Un buon esempio di tutto questo può essere visto sulla ASUS Zenith Extreme.

Ci sono 12 ulteriori linee che possono essere usate per storage PCIe o SATA e suddivise in 3 connessioni da 4 linee ciascuna. Ciò conferisce all’utente l’accesso a soluzioni di storage dalla bandwidth estremamente elevata, ed è notizia recente che, con un aggiornamento BIOS e software, sarà possibile utilizzare tali connessioni per sistemi RAID hardware. I processori Threadripper supportano inoltre 8 porte USB 3.1 Gen1 native e un codec audio ad alta definizione.
Il chipset X399 stesso non è stato lasciato allo scoperto, ovviamente, in quanto esso supporta nativamente fino ad 8 porte SATA III, 5 porte USB 3.1 Gen1 e 7 porte USB 2.0. In aggiunta, ci sono 8 linee PCIe Gen2 disponibili per il collegamento di dispositivi come un modulo Bluetooth, più slot per schede di espansione e così via. La parola d’ordine però qui è “fino a” per tutti i collegamenti visto che starà al produttore della scheda madre quali porte e/o connessioni abilitare sui propri design. Ciò che AMD ci mostra nel suo diagramma (più sopra in pagina) è la versione “fully enabled” che dovremmo vedere raramente nella pratica.
Galleria fotografica: ASRock X399 Taichi–>
Ecco una serie di immagini che ritraggono la ASRock X399 Taichi:






La sezione di alimentazione è, come già citato precedentemente, identica a quella della X399 Professional Gaming, pertanto non abbiamo smontato i dissipatori per mostrarvi le fasi, visto che l’abbiamo già fatto QUI.
Configurazione di sistema e metodologia di test–>
La configurazione utilizzata per i test è la seguente:
| CPU | AMD Ryzen Threadripper 1950X |
|---|---|
| Heatsink | Noctua NH-U12S TR4-SP3 |
| Mainboard | ASRock X399 Taichi |
| RAM | G.Skill TridentZ RGB 3466 MHz C16 32 GB |
| VGA | Sapphire Radeon RX560 Pulse 4 GB OC |
| Sound Card | – |
| HDD/SSD | Patriot Hellfire 240 GB M.2 NVMe SSD |
| PSU | Seasonic Prime Gold 850 W |
| Case | Streacom BC1 Open Benchtable |
| Monitor | Acer CB280HK 4K Display |
| Keyboard | Cooler Master MasterKeys Pro L GTX Edition |
| Mouse | Razer Naga Hex V2 |
| OS | Windows 10 Pro x64 Fall Creators Update |
Benchmark sintetici:
- SuperPI 1.5 mod XS 1M e 32M
- WPrime 1.55 32M e 1024M
- Cinebench R11.5
- Cinebench R15
- AIDA64 Photoworxx
- AIDA64 ZLib
- AIDA64 AES
- AIDA64 Hash
- AIDA64 VP8
- AIDA64 SinJulia
Benchmark grafici:
- Ashes of the Singularity, preset Crazy, 1080p, benchmark CPU Focused (DX12)
- 3DMark Fire Strike (DX11)
- 3DMark Time Spy (DX12)
Benchmark sintetici: AIDA64–>
AIDA64 è uno strumento di analisi, diagnostica e benchmarking per sistemi Windows (e più recentemente, Android), che dispone di una vastissima suite di benchmark e che è diventato, nel tempo, un software di riferimento tra utenti e professionisti per il moitoraggio e il confronto di tutto l’hardware all’interno del proprio PC.
CPU Photoworxx
Questo benchmark esegue diverse operazioni comuni utilizzate durante il fotoritocco. Per la precisione, esegue un numero di operazioni di modifica su un’immagine RGB molto larga.
Questo benchmark stressa le unità SIMD della CPU e il sottosistema delle RAM. CPU Photoworks usa laddove presenti le librerie di istruzioni x87, MMX, MMX+, 3DNow!, 3DNow!+, SSE, SSE2, SSE3, SSE4.1, SSE4A, AVX, AVX2 e XOP e trae beneficio di NUMA, HyperThreading, sistemi multiprocessore e multicore.
| MPixel/s | |
|---|---|
| ASRock Fatal1ty X399 Professional Gaming (1920X) | 44.274 |
| ASRock X399 Taichi (1950X) | 43.992 |
| ASUS Zenith Extreme (1950X) | 43.535 |
| Gigabyte X399 AORUS Gaming 7 (1950X) | 39.093 |
| ASRock Fatal1ty X299 Professional Gaming i9 XE (i9 7920X) | 36.773 |
| ASRock Fatal1ty X99 Professional Gaming i7 (i7 5960X) | 36.520 |
| ASRock X299 Killer SLI/ac (i5 7640X) | 26.192 |
| ASRock X299 Taichi (i5 7640X) | 25.943 |
| ASRock Fatal1ty X299 Professional Gaming i9 (i5 7640X) | 25.850 |
| ASRock Fatal1ty Z370 Gaming-ITX/ac (i7 8700K) | 25.142 |
| Gigabyte AORUS X370-Gaming K7 (1800X) | 24.733 |
| ASRock Fatal1ty X370 Professional Gaming (1800X) | 23.611 |
| ASRock X370 Killer SLI (1800X) | 23.556 |
| ASRock Fatal1ty X370 Gaming K4 (1800X) | 23.555 |
| ASRock Fatal1ty AB350 Gaming K4 (1800X) | 23.307 |
| ASRock Fatal1ty X370 Gaming-ITX/ac (1800X) | 22.369 |
| ASRock Fatal1ty AB350 Gaming K4 (1600) | 22.127 |
| ASRock Fatal1ty AB350 Gaming K4 (1400) | 16.179 |
| ASRock 990FX Extreme3 (FX-8350) | 12.328 |
CPU ZLib Benchmark
Questo benchmark integer misura le prestazioni combinate di CPU e memorie tramite la libreria di compressione open source ZLib. Il test CPU ZLib utilizza solo le istruzioni base x86 ma ciononostante è un buon indicatore delle prestazioni generali del sistema.
MB/s
ASRock X399 Taichi (1950X)
1.332,4
Gigabyte X399 AORUS Gaming 7 (1950X)
1.329
ASUS Zenith Extreme (1950X)
1.317,2
ASRock Fatal1ty X399 Professional Gaming (1920X)
1.043,7
ASRock Fatal1ty X299 Professional Gaming i9 XE (i9 7920X)
1.030,4
ASRock Fatal1ty X370 Professional Gaming (1800X)
690,7
Gigabyte AORUS X370-Gaming K7 (1800X)
686,8
ASRock Fatal1ty AB350 Gaming K4 (1800X)
683,2
ASRock X370 Killer SLI (1800X)
678,3
ASRock Fatal1ty X370 Gaming K4 (1800X)
677,1
ASRock Fatal1ty X370 Gaming-ITX/ac (1800X)
675,8
ASRock Fatal1ty X99 Professional Gaming i7 (i7 5960X)
601,2
ASRock Fatal1ty Z370 Gaming-ITX/ac (i7 8700K)
574,5
ASRock Fatal1ty AB350 Gaming K4 (1600)
473,4
ASRock 990FX Extreme3 (AMD FX-8350)
340,8
ASRock Fatal1ty AB350 Gaming K4 (1400)
297,7
ASRock X299 Taichi (i5 7640X)
294,5
ASRock Fatal1ty X299 Professional Gaming i9 (i5 7640X)
294,3
ASRock X299 Killer SLI/ac (i5 7640X)
294,1
CPU AES Benchmark
Questo benchmark misura le prestazioni della CPU utilizzando la crittografia dati AES (Advanced Encryption Standard). In crittografia, AES è uno standard di crittaggio a chiave simmetrica, ed è utilizzato in svarati strumenti di compressione come 7-zip, WinRAR, WinZIP e anche in soluzioni di encrypting come BitLocker (Windows), FileVault (Mac OSX) e TrueCrypt (open source).
Il test AES Benchmark usa le appropriate istruzioni x86, MMX e SSE 4.1, ed è accelerato a livello hardware su processori abilitati tramite il set di istruzioni AES-NI. Questo test rileva e sfrutta HyperThreading, sistemi multiprocessore e multicore.
MB/s
Gigabyte X399 AORUS Gaming 7 (1950X)
124.739
ASRock X399 Taichi (1950X)
124.415
ASUS Zenith Extreme (1950X)
124.335
ASRock Fatal1ty X399 Professional Gaming (1920X)
98.841
ASRock Fatal1ty X370 Professional Gaming (1800X)
64.972
ASRock Fatal1ty X370 Gaming K4 (1800X)
64.934
ASRock X370 Killer SLI (1800X)
64.873
Gigabyte AORUS X370-Gaming K7 (1800X)
64.400
ASRock Fatal1ty AB350 Gaming K4 (1800X)
64.224
ASRock Fatal1ty X370 Gaming-ITX/ac (1800X)
63.730
ASRock Fatal1ty X299 Professional Gaming i9 XE (i9 7920X)
52.015
ASRock Fatal1ty AB350 Gaming K4 (1600)
45.334
ASRock Fatal1ty X99 Professional Gaming i7 (i7 5960X)
31.715
ASRock Fatal1ty Z370 Gaming-ITX/ac (i7 8700K)
29.426
ASRock Fatal1ty AB350 Gaming K4 (1400)
28.434
ASRock X299 Taichi (i5 7640X)
18.560
ASRock X299 Killer SLI/ac (i5 7640X)
18.559
ASRock Fatal1ty X299 Professional Gaming i9 (i5 7640X)
18.543
ASRock 990FX Extreme3 (AMD FX-8350)
17.083
CPU Hash Benchmark
Questo benchmark misura le prestazioni CPU utilizzando l’algoritmo di hashing SHA1 definito nella FIPSPS 180-3. Il codice dietro questo benchmark è compilato in Assembly, e più importante, utilizza librerie di istruzioni MMX, MMX+, SSE, SSE2, SSSE3 e AVX, con prestazioni superiori su processori che supportano tali instruction sets.e on supporting processors.
MB/s
Gigabyte X399 AORUS Gaming 7 (1950X)
44.605
ASUS Zenith Extreme (1950X)
44.421
ASRock X399 Taichi (1950X)
43.792
ASRock Fatal1ty X399 Professional Gaming (1920X)
33.271
ASRock Fatal1ty X370 Professional Gaming (1800X)
22.368
Gigabyte AORUS X370-Gaming K7 (1800X)
22.353
ASRock Fatal1ty AB350 Gaming K4 (1800X)
22.313
ASRock Fatal1ty X370 Gaming K4 (1800X)
22.309
ASRock X370 Killer SLI (1800X)
22.309
ASRock Fatal1ty X370 Gaming-ITX/ac (1800X)
22.243
ASRock Fatal1ty AB350 Gaming K4 (1600)
15.372
ASRock Fatal1ty X299 Professional Gaming i9 XE (i9 7920X)
13.088
ASRock Fatal1ty AB350 Gaming K4 (1400)
9.648
ASRock Fatal1ty Z370 Gaming-ITX/ac (i7 8700K)
7.402
ASRock Fatal1ty X99 Professional Gaming i7 (i7 5960X)
7.146
ASRock X299 Taichi (i5 7640X)
4.592
ASRock Fatal1ty X299 Professional Gaming i9 (i5 7640X)
4.584
ASRock X299 Killer SLI/ac (i5 7640X)
4.578
ASRock 990FX Extreme3 (AMD FX-8350)
4.065
FPU VP8 / SinJulia Benchmarks
Il benchmark di AIDA FPU VP8 misura le prestazioni di compressione video utilizzando il codec di Google VP8 (utilizzato per i file WebM) aggiornato alla versione 0.9.5 e stressa l’FPU (Floating Point Unit) della CPU. Il test codifica fotogrammi video dalla risoluzione di 1280×720 in 1 pass ad un bitrate di 8 Mbps con impostazioni di qualità massima.
Il contenuto dei fotogrammi viene poi generato dal modulo FPU Julia. Il codice che gestisce questo benchmark utilizza librerie MMX, SSE2 e SSSE3. SinJulia, invece, misura le prestazioni in floating point a precisione estesa (conosciuta anche come 80-bit) tramite il calcolo di un singolo fotogrammi di un frattale “Julia” modificato. Il codice di questo benchmark è scritto in Assembly, e utilizza istruzioni trigonometriche ed esponenziali x87.
VP8
SinJulia
Gigabyte X399 AORUS Gaming 7 (1950X)
8.578
25.309
ASUS Zenith Extreme (1950X)
7.707
25.202
ASRock X399 Taichi (1950X)
8.025
25.115
ASRock Fatal1ty X399 Professional Gaming (1920X)
7.794
18.888
ASRock Fatal1ty X299 Professional Gaming i9 XE (i9 7920X)
8.394
13.760
Gigabyte AORUS X370-Gaming K7 (1800X)
7.873
12.686
ASRock Fatal1ty X370 Professional Gaming (1800X)
7.747
12.684
ASRock Fatal1ty X370 Gaming K4 (1800X)
7.340
12.665
ASRock Fatal1ty AB350 Gaming K4 (1800X)
7.366
12.658
ASRock X370 Killer SLI (1800X)
7.910
12.657
ASRock Fatal1ty X370 Gaming-ITX/ac (1800X)
7.913
12.617
ASRock Fatal1ty X99 Professional Gaming i7 (i7 5960X)
6.693
8.895
ASRock Fatal1ty AB350 Gaming K4 (1600)
6.720
8.724
ASRock Fatal1ty Z370 Gaming-ITX/ac (i7 8700K)
8.458
7.787
ASRock Fatal1ty AB350 Gaming K4 (1400)
6.115
5.472
ASRock X299 Killer SLI/ac (i5 7640X)
7.290
3.563
ASRock Fatal1ty X299 Professional Gaming i9 (i5 7640X)
6.894
3.562
ASRock X299 Taichi (i5 7640X)
6.825
3.561
ASRock 990FX Extreme3 (AMD FX-8350)
4.446
2.768
Benchmark sintetici 2D: SuperPI e WPrime–>
SuperPI
Un metodo tradizionale per verificare le prestazioni del proprio PC è utilizzare SuperPI mod 1.5 XS: il programma si occupa di calcolare dalle 16k ai 32M di cifre dopo la virgola del π, con una scalabilità clock per clock davvero sorprendente per un programma creato nel 1995. Il programma calcola l’efficienza single-threaded piuttosto che quella multithreaded:
1M
32M
ASRock Fatal1ty Z370 Gaming-ITX/ac (i7 8700K)
7,837
429,03
ASRock Fatal1ty Z270 Gaming K6 (i5 7600K)
8,809
450,771
ASRock Fatal1ty Z170 Gaming K6 (i7 6700K)
8,673
451,345
ASRock Fatal1ty X299 Professional Gaming i9 XE (i9 7920X)
8,454
454,878
ASRock X299 Taichi (i5 7640X)
8,713
465,956
ASRock X299 Killer SLI/ac (i5 7640X)
8,741
469,722
ASRock Fatal1ty X299 Professional Gaming i9 (i5 7640X)
8,745
470,83
ASRock Z97E-ITX/ac (i7 4770K)
9,236
478,25
ASRock Fatal1ty X99 Professional Gaming i7 (i7 5960X)
10,412
554,754
Gigabyte AORUS X370-Gaming K7 (1800X)
10,877
568,897
ASUS Zenith Extreme (1950X)
10,331
573,239
ASRock X370 Killer SLI (1800X)
10,33
573,679
ASRock Fatal1ty X399 Professional Gaming (1920X)
10,701
575,71
ASRock Fatal1ty AB350 Gaming K4 (1800X)
10,626
582,634
ASRock Fatal1ty X370 Gaming K4 (1800X)
10,969
583,774
ASRock Fatal1ty X370 Professional Gaming (1800X)
10,283
584,619
Gigabyte X399 AORUS Gaming 7 (1950X)
10,595
595,635
ASRock X399 Taichi (1950X)
10,722
595,741
ASRock Fatal1ty X370 Gaming-ITX/ac (1800X)
10,654
595,849
ASRock Fatal1ty AB350 Gaming K4 (1600)
12,846
628,985
ASRock Fatal1ty AB350 Gaming K4 (1400)
12,314
701,167
ASRock 990FX Extreme3 (AMD FX-8350)
27,783
WPrime
Insieme al calcolo delle cifre dopo la virgola del π, un altro metodo valido per verificare le performance del proprio PC è utilizzare WPrime, da noi usato nella versione 1.55 (la stessa valida per i benchmark di HWBot), che consente di trovare dai 32M ai 1024M di numeri primi. Il programma scala enormemente in presenza di CPU multi-core, rappresentando un valido benchmark per il calcolo dell’efficienza multithreaded:
32M
1024M
ASUS Zenith Extreme (1950X)
2,931
48,169
ASRock X399 Taichi (1950X)
2,758
49,01
Gigabyte X399 AORUS Gaming 7 (1950X)
2,579
50,006
ASRock Fatal1ty X299 Professional Gaming i9 XE (i9 7920X)
3,269
58,742
ASRock Fatal1ty X399 Professional Gaming (1920X)
2,978
61,858
ASRock Fatal1ty X370 Professional Gaming (1800X)
3,672
90,294
ASRock Fatal1ty AB350 Gaming K4 (1800X)
3,344
90,527
ASRock Fatal1ty X370 Gaming K4 (1800X)
3,357
90,59
ASRock X370 Killer SLI (1800X)
3,328
90,622
ASRock Fatal1ty X370 Gaming-ITX/ac (1800X)
3,442
90,632
Gigabyte AORUS X370-Gaming K7 (1800X)
3,453
90,638
ASRock Fatal1ty Z370 Gaming-ITX/ac (i7 8700K)
3,41
98,762
ASRock Fatal1ty X99 Professional Gaming i7 (i7 5960X)
3,82
106,806
ASRock Fatal1ty AB350 Gaming K4 (1600)
4,516
131,941
ASRock Fatal1ty Z170 Gaming K6 (i7 6700K)
4,902
152,039
ASRock Z97E-ITX/ac (i7 4770K)
5,955
182,555
ASRock Fatal1ty Z270 Gaming K6 (i5 7600K)
6,616
200,487
ASRock X299 Taichi (i5 7640X)
6,425
200,637
ASRock X299 Killer SLI/ac (i5 7640X)
6,431
201,155
ASRock Fatal1ty X299 Professional Gaming i9 (i5 7640X)
6,463
201,522
ASRock Fatal1ty AB350 Gaming K4 (1400)
6,861
208,375
ASRock 990FX Extreme3 (AMD FX-8350)
8,629
262,33
Benchmark sintetici: Cinebench R11.5 e Cinebench R15–>
Cinebench R11.5 e R15
Come da tradizione (e in questo caso particolare, utilizzarli è obbligatorio, come vedrete), fanno capolino tra i benchmark con cui testiamo le prestazioni di un sistema anche le ultime due release di Cinebench, rispettivamente la R11.5 e la R15. Entrambi i test utilizzano un approccio simile di testing: i benchmark utilizzano svariati algoritmi per stressare tutti i core disponibili per renderizzare una scena 3D fotorealistica nel minor tempo possibile.
In particolare, con il benchmark nella versione R15, la scena del test contiene approssimativamente 2000 oggetti contenenti più di 300’000 poligoni totali, e usa riflessi sia definiti che sfocati, ombre e luci a zona, shaders procedurali, antialiasing e tanto altro ancora. Questo benchmark può effettuare misurazioni fino ad un massimo di 64 threads, con il risultato che viene fornito in punti (Points): ovviamente, più punti totalizzate, più potente sarà il vostro sistema:
Single Thread
Multithread
ASUS Zenith Extreme (1950X)
1,86
32,91
Gigabyte X399 AORUS Gaming 7 (1950X)
1,79
32,7
ASRock X399 Taichi (1950X)
1,84
32,5
ASRock Fatal1ty X299 Professional Gaming i9 XE (i9 7920X)
2,08
26,97
ASRock Fatal1ty X399 Professional Gaming (1920X)
1,83
23,01
ASRock Fatal1ty X370 Gaming-ITX/ac (1800X)
1,74
18,13
Gigabyte AORUS X370-Gaming K7 (1800X)
1,79
18,08
ASRock X370 Killer SLI (1800X)
1,83
18,06
ASRock Fatal1ty AB350 Gaming K4 (1800X)
1,82
18,04
ASRock Fatal1ty X370 Professional Gaming (1800X)
1,75
17,96
ASRock Fatal1ty X370 Gaming K4 (1800X)
1,83
17,92
ASRock Fatal1ty Z370 Gaming-ITX/ac (i7 8700K)
2,33
15,78
ASRock Fatal1ty X99 Professional Gaming i7 (i7 5960X)
1,54
14,49
ASRock Fatal1ty AB350 Gaming K4 (1600)
1,64
12,56
ASRock Fatal1ty Z170 Gaming K6 (i7 6700K)
10,26
ASRock Z97E-ITX/ac (i7 4770K)
8,66
ASRock Fatal1ty Z270 Gaming K6 (i5 7600K)
8,19
ASRock X299 Taichi (i5 7640X)
2,07
8,14
ASRock X299 Killer SLI/ac (i5 7640X)
2,07
8,1
ASRock Fatal1ty X299 Professional Gaming i9 (i5 7640X)
2,04
8,06
ASRock Fatal1ty AB350 Gaming K4 (1400)
1,52
7,78
ASRock 990FX Extreme3 (FX-8350)
1,04
6,86
Single Thread
Multithread
ASRock X399 Taichi (1950X)
171
3.002
ASUS Zenith Extreme (1950X)
169
2.990
Gigabyte X399 AORUS Gaming 7 (1950X)
158
2.912
ASRock Fatal1ty X299 Professional Gaming i9 XE (i9 7920X)
183
2.507
ASRock Fatal1ty X399 Professional Gaming (1920X)
165
2.438
Gigabyte AORUS X370-Gaming K7 (1800X)
160
1.650
ASRock Fatal1ty X370 Gaming-ITX/ac (1800X)
155
1.644
ASRock Fatal1ty X370 Gaming K4 (1800X)
164
1.638
ASRock Fatal1ty AB350 Gaming K4 (1800X)
163
1.632
ASRock X370 Killer SLI (1800X)
163
1.627
ASRock Fatal1ty X370 Professional Gaming (1800X)
149
1.600
ASRock Fatal1ty Z370 Gaming-ITX/ac (i7 8700K)
207
1.431
ASRock Fatal1ty X99 Professional Gaming i7 (i7 5960X)
136
1.325
ASRock Fatal1ty AB350 Gaming K4 (1600)
149
1.147
ASRock Fatal1ty Z170 Gaming K6 (i7 6700K)
941
ASRock Z97E-ITX/ac (i7 4770K)
824
ASRock X299 Killer SLI/ac (i5 7640X)
180
710
ASRock X299 Taichi (i5 7640X)
183
708
ASRock Fatal1ty X299 Professional Gaming i9 (i5 7640X)
181
707
ASRock Fatal1ty Z270 Gaming K6 (i5 7600K)
705
ASRock Fatal1ty AB350 Gaming K4 (1400)
135
694
ASRock 990FX Extreme3 (AMD FX-8350)
94
634
Benchmark 3D: 3DMark, Ashes of the Singularity–>
3DMark Fire Strike e Time Spy
In concomitanza con il lancio di Windows 8, Futuremark ha lanciato il nuovo 3DMark, chiamato appunto 3DMark, senza alcun numero riconoscitivo, a segnare la forte integrazione che ha con qualsiasi sistema, da Android a Windows a iOS a OSX, dando per la prima volta la possibilità di paragonare le prestazioni su smartphone e PC fisso in maniera schematizzata e professionale. Il benchmark dispone di svariati test, di cui utilizziamo i più intensivi per mettere alla prova le schede video.
Tra questi, il più impegnativo è il Fire Strike, che spinge la tessellazione a livelli davvero elevati, e che “vanta” due versioni ancora più spinte: Extreme (con scene pre-renderizzate a 2560×1440) ed Ultra (scene pre-renderizzate a 3840×2160, ovvero 4K). Purtroppo, a nostra disposizione
| CPU Score | |
|---|---|
| ASUS Zenith Extreme (1950X) | 27.045 |
| ASRock X399 Taichi (1950X) | 26.924 |
| Gigabyte X399 AORUS Gaming 7 (1950X) | 26.322 |
| ASRock Fatal1ty X299 Professional Gaming i9 XE (i9 7920X) | 23.514 |
| ASRock Fatal1ty X399 Professional Gaming (1920X) | 21.032 |
| ASRock Fatal1ty X370 Gaming-ITX/ac (1800X) | 19.385 |
| Gigabyte AORUS X370-Gaming K7 (1800X) | 19.381 |
| ASRock Fatal1ty X370 Gaming K4 (1800X) | 19.213 |
| ASRock Fatal1ty AB350 Gaming K4 (1800X) | 19.198 |
| ASRock Fatal1ty Z370 Gaming-ITX/ac (i7 8700K) | 19.024 |
| ASRock X370 Killer SLI (1800X) | 18.821 |
| ASRock Fatal1ty X370 Professional Gaming (1800X) | 18.769 |
| ASRock Fatal1ty X99 Professional Gaming i7 (i7 5960X) | 16.667 |
| ASRock Fatal1ty AB350 Gaming K4 (1600) | 15.632 |
| ASRock Fatal1ty AB350 Gaming K4 (1400) | 10.596 |
| ASRock X299 Killer SLI/ac (i5 7640X) | 9.584 |
| ASRock X299 Taichi (i5 7640X) | 9.473 |
| ASRock Fatal1ty X299 Professional Gaming i9 (i5 7640X) | 9.364 |
Recentemente, invece, è stato introdotto il benchmark Time Spy, che testa le prestazioni delle GPU sfruttando le nuove API Microsoft DirectX 12, con scene pre-renderizzate a 2560×1440:
| CPU Score | |
|---|---|
| ASUS Zenith Extreme (1950X) | 11.690 |
| ASRock X399 Taichi (1950X) | 11.526 |
| ASRock Fatal1ty X299 Professional Gaming i9 XE (i9 7920X) | 11.095 |
| Gigabyte X399 AORUS Gaming 7 (1950X) | 11.054 |
| ASRock Fatal1ty X399 Professional Gaming (1920X) | 10.050 |
| Gigabyte AORUS X370-Gaming K7 (1800X) | 8.448 |
| ASRock Fatal1ty X370 Professional Gaming (1800X) | 8.377 |
| ASRock Fatal1ty X370 Gaming K4 (1800X) | 8.320 |
| ASRock X370 Killer SLI (1800X) | 8.306 |
| ASRock Fatal1ty X370 Gaming-ITX/ac (1800X) | 8.229 |
| ASRock Fatal1ty AB350 Gaming K4 (1800X) | 8.175 |
| ASRock Fatal1ty Z370 Gaming-ITX/ac (i7 8700K) | 7.989 |
| ASRock Fatal1ty X99 Professional Gaming i7 (i7 5960X) | 7.989 |
| ASRock Fatal1ty AB350 Gaming K4 (1600) | 5.650 |
| ASRock Fatal1ty X299 Professional Gaming i9 (i5 7640X) | 4.429 |
| ASRock X299 Taichi (i5 7640X) | 4.424 |
| ASRock X299 Killer SLI/ac (i5 7640X) | 4.397 |
| ASRock Fatal1ty AB350 Gaming K4 (1400) | 3.466 |
Ashes of the Singularity
Ashes of the Singularity è quello che Stardock (la software house creatrice del gioco) definisce come un gioco strategico di warfare planetario, e con le sue mappe enormi e le migliaia di unità a schermo durante i combattimenti full-scale, non si può far altro che dare ragione all’azienda.
Ciò che viene spesso associato ad Ashes è l’incredibile onere che applica ai sistemi grafici (e non solo, il gioco è famelico di core e GHz), tramite l’utilizzo di DirectX 11 e 12. Il preset Crazy è in grado di mettere in ginocchio qualsiasi GPU in commercio già alla risoluzione Full HD. Il gioco si avvale del supporto alle tecnologie AMD, prendendo spunto dal motore grafico Nitrous utilizzato in uno dei primi benchmark per Mantle, Star Swarm:
| FPS (CPU) | |
|---|---|
| ASRock Fatal1ty X99 Professional Gaming i7 (i7 5960X) | 56,5 |
| ASRock Fatal1ty Z370 Gaming-ITX/ac (i7 8700K) | 55,7 |
| ASUS Zenith Extreme (1950X) | 55 |
| ASRock Fatal1ty X299 Professional Gaming i9 XE (i9 7920X) | 54,9 |
| Gigabyte X399 AORUS Gaming 7 (1950X) | 52,9 |
| ASRock X399 Taichi (1950X) | 50,4 |
| ASRock Fatal1ty X399 Professional Gaming (1920X) | 47,3 |
| Gigabyte AORUS X370-Gaming K7 (1800X) | 47,1 |
| ASRock Fatal1ty AB350 Gaming K4 (1800X) | 41,7 |
| ASRock Fatal1ty X370 Professional Gaming (1800X) | 41,5 |
| ASRock X370 Killer SLI (1800X) | 41,3 |
| ASRock Fatal1ty X370 Gaming K4 (1800X) | 40,3 |
| ASRock X299 Killer SLI/ac (i5 7640X) | 34,6 |
| ASRock X299 Taichi (i5 7640X) | 34,1 |
| ASRock Fatal1ty X299 Professional Gaming i9 (i5 7640X) | 33,6 |
| ASRock Fatal1ty AB350 Gaming K4 (1600) | 32,8 |
| ASRock Fatal1ty AB350 Gaming K4 (1400) | 22,6 |
| ASRock Fatal1ty X370 Gaming-ITX/ac (1800X) | 0 |
Considerazioni finali–>
[conclusione]
[titolo]Design, qualità costruttiva e software[/titolo]
Richiamando le linee riportate dalle altre schede madri della famiglia Taichi, la ASRock X399 Taichi presenta un design quasi identico (anche nei colori) alla Fatal1ty X399 Professional Gaming, tranne ovviamente per il PCB e il dissipatore del chipset, tutti in stile Ying Yang con il grigio chiaro e il grigio scuro che fanno da contrasto.
A livello di qualità costruttiva, ci troviamo di fronte ad un “quasi-clone” della Fatal1ty X399 Professional Gaming, il che è una cosa grandiosa, visto che quella scheda costa ben più di 100€ in più, per via della scheda 10 Gigabit Ethernet assente sulla Taichi. La sezione di alimentazione è davvero robusta, con un sacco di Ampere a disposizione per qualsiasi tipo di overclock, sia ad aria che a liquido.
Il software è ormai maturo e permette di gestire le ventole, l’illuminazione RGB e anche l’overclock da Windows, anche se, ovviamente, consigliamo di effettuarlo tramite BIOS per il massimo risultato.
[voto=”9″]
[/conclusione]
[conclusione]
[titolo]Performance e overclock[/titolo]
L’ASRock X399 Taichi si è comportata ottimamente sia in single thread che in multithread, scambiando colpi sia con la scheda, dal prezzo simile, di Gigabyte, la X399 Gaming 7, che con la ASUS Zenith Extreme, che presenta un costo di gran lunga superiore. Le capacità in overclock, invece, rispecchiano praticamente al 100% sia quelle della Zenith Extreme che della Professional Gaming di ASRock stessa, grazie allo stesso tipo di VRM e controller (sebbene quello ASUS sia una versione “custom” in termini di firmware) delle due schede, con quindi una capacità di erogare ben 480 A per la sola CPU, una quantità ben sufficiente per qualsiasi tipo di overclock, che sia ad aria, liquido o persino sotto le estreme condizioni dettate dall’azoto liquido.
[voto=”10″]
[/conclusione]
[conclusione]
[titolo]Compatibilità e connettività[/titolo]
La connettività di questa scheda è ampia, con 8 porte SATA 3, fino a 18 porte USB, 3 slot Ultra M.2 da 32 Gbps ciascuno, uno slot U.2 (raro ma sempre ben accetto), Wifi 802.11ac (sebbene a soli 433 Mbps), due scheda Gigabit Ethernet LAN, e ovviamente supporto a configurazioni multi scheda fino a 4 GPU, memorie DDR4 fino a 128 GB e tutte le CPU basate su socket sTR4 finora lanciate.
[voto=”9″]
[/conclusione]
[conclusione]
[titolo]Prezzo[/titolo]
Il prezzo della ASRock X399 Taichi è di circa 340 € su Amazon (clicca QUI per acquistarla tramite il nostro referral), un prezzo comparabile a quello della Gaming 7 di Gigabyte recentemente recensita, tra i più bassi nel parco schede X399 in commercio, e quindi risulta davvero un acquisto consigliato qualora voleste creare una macchina potente adatta ad ogni situazione basata su CPU Threadripper.
Come al solito, vi invitiamo ad acquistare presso i rivenditori ufficiali ASRock, in quanto pur presentando un prezzo superiore ai VAT Player (coloro che evadono l’iva tramite meccanismi al limite della legalità), forniscono supporto post-vendita/RMA, cosa che suddetti rivenditori non ufficiali non garantiscono.
[voto=”10″]
[/conclusione]
Concludendo, la ASRock X399 Taichi è una scheda madre eccellente in ogni campo, con design e prestazioni ai massimi livelli ed un prezzo tutto sommato accettabile, visto tutto quello che offre soprattutto in rapporto a schede madri più costose ma non proporzionalmente più performanti. Per questo motivo, diamo ad essa il nostro Hardware Platinum Award, sperando che ASRock lavori sui pochi fattori in cui la scheda ha delle mancanze, come una connettività WiFi migliore e più opzioni per l’illuminazione RGB.

Per oggi è tutto, ringraziamo come sempre ASRock (thanks Peter!) per il sample oggi recensito.
Per leggere ogni settimana nuove recensioni seguiteci sui nostri social networks:
La recensione
ASRock X399 Taichi
La ASRock X399 Taichi è una scheda madre equilibrata, dalle prestazioni elevate, un design accattivante ed un rapporto qualità/prezzo di gran lunga superiore alla maggior parte delle schede X399 in commercio, anche della stessa ASRock.
Pro
- Prezzo davvero competitivo per una mainboard X399
- Presenta quasi interamente le features della Professional Gaming, più costosa
- Sezione di alimentazione corposa
Contro
- Modalità di illuminazione RGB anonime rispetto alla concorrenza
ASRock X399 Taichi Prezzi
Raccogliamo informazioni da vari negozi per indicare il prezzo migliore




![[COMPUTEX 2026] be quiet! svela tanti nuovi prodotti al Computex](https://www.rehwolution.it/wordpress/wp-content/uploads/2026/06/bq-computex2026-pure-base-803-4x5-5-350x250.jpg)
![[COMPUTEX 2026] Noctua e Carbice insieme per il raffreddamento DIY](https://www.rehwolution.it/wordpress/wp-content/uploads/2026/06/noctua_nt_cp1_am5_4_announcement_post_v4-scaled-350x250.jpg)